Spark JDBC 及 join BNLJ 调优
前言
在用 Spark load impala 表做非等值连接时碰到了一些问题。表现为加载源数据慢及做 join 操作异常慢。本文记录逐步解决这些问题的过程。
记录
需求其实很简单,存在两张表,表A 和表B。
表A schema 如下。login_as_cfid 字段存在于表B 中的 $device_id_list 列表中,数据量大概 150w
1 | root |
表B schema 如下,$device_id_list 为设备列表,其实是以 \n 分隔的字符串。。。。数据量大概 400w
1 | root |
现在需要找到 first_id 和 second_id 的对应关系。首先很自然的想到就是两张表做 join,join 的连接条件如下。
1 | array_contains(col("$device_id_list"), $"login_as_cfid") |
emmn,很快便有了以下代码
1 | val load_imapla:(String, String) => Dataset[Row] = (impala_url, table) => {spark.read |
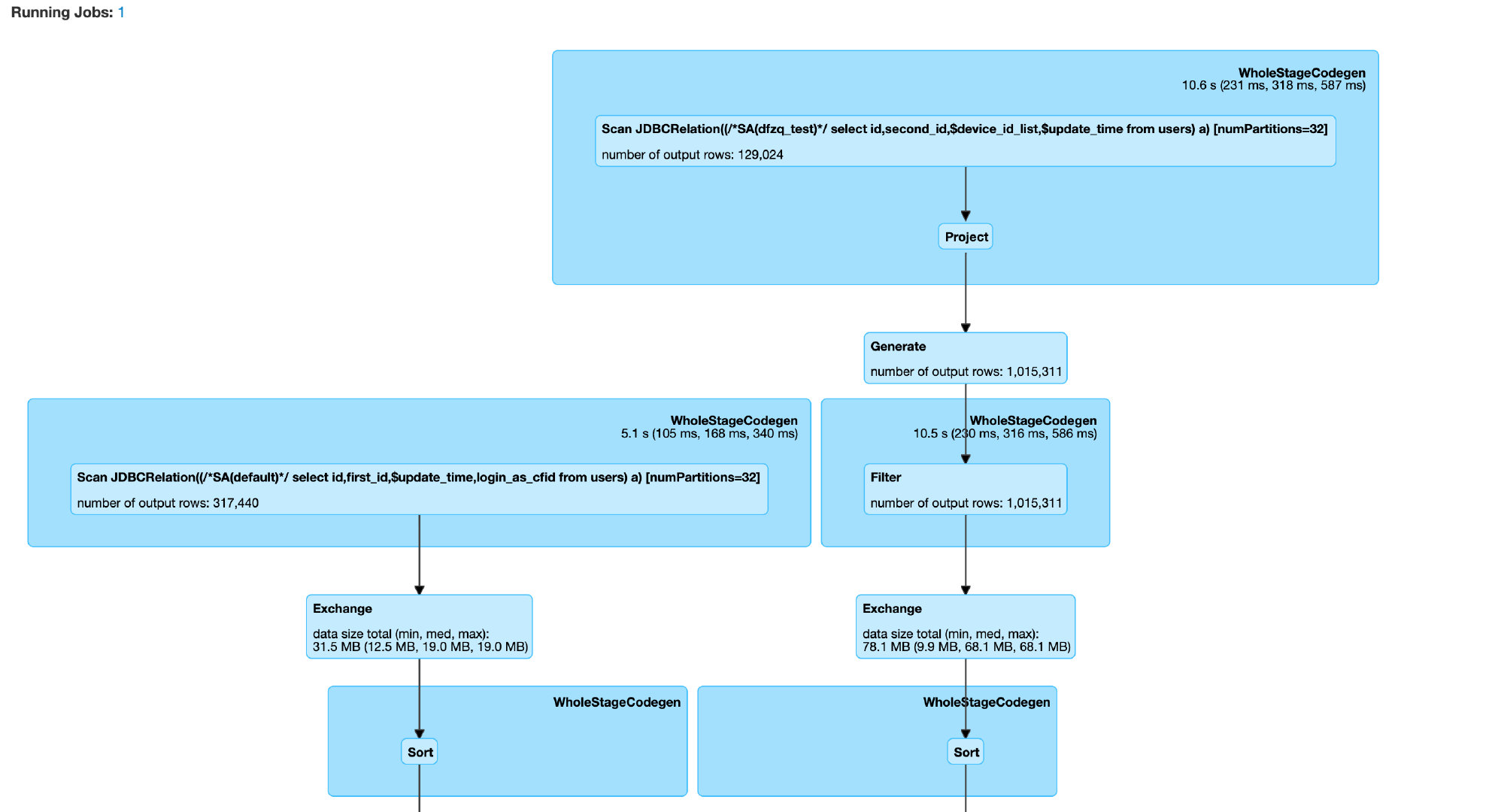
好了,那现在就跑一把看看,等了快1h左右还没有跑完,去 Spark UI 上看执行 DAG 图如下。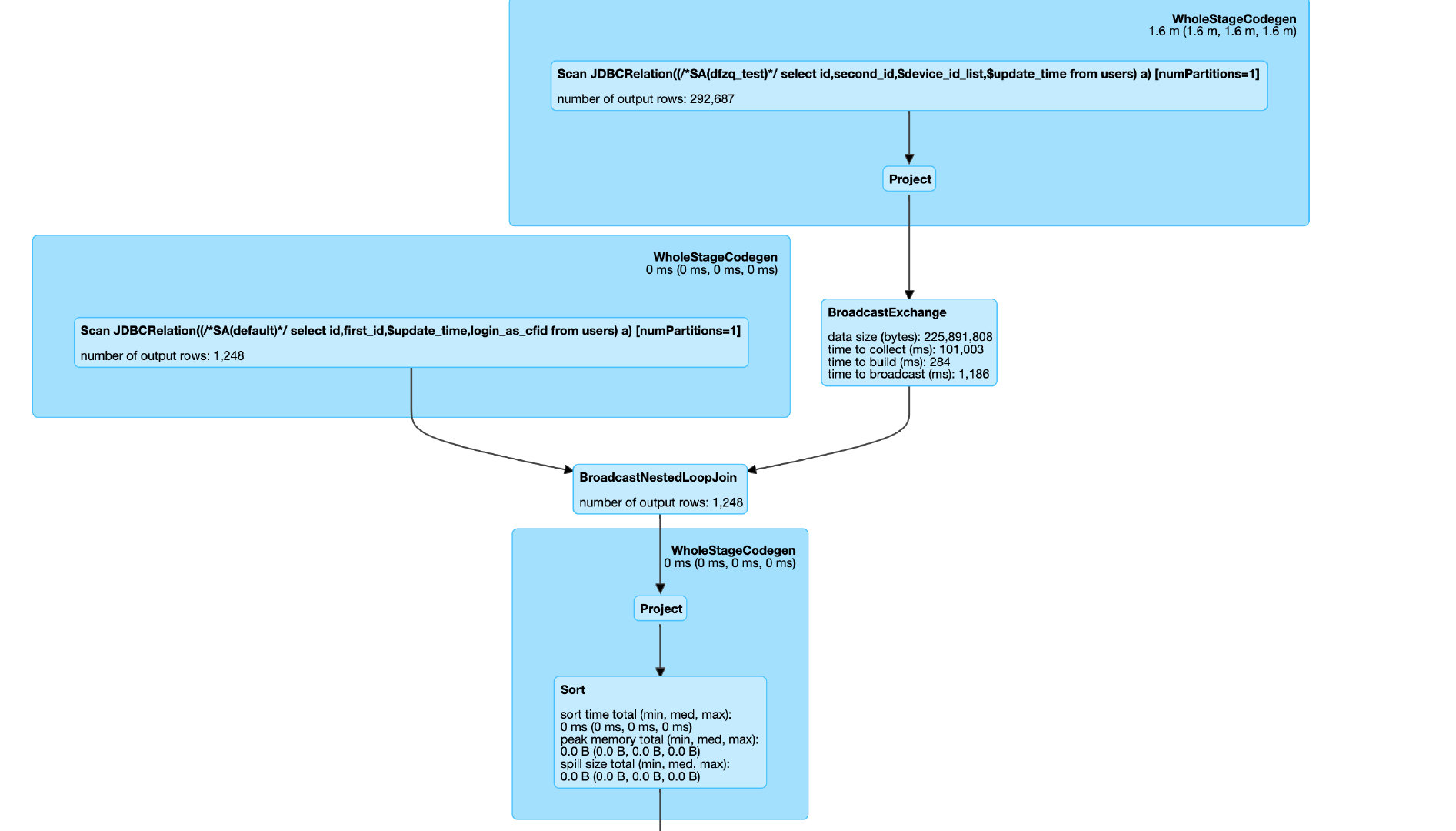
可以看到耗时较长的原因有以下两点,其中 BNLJ 巨慢,是主要原因
- 数据源端,load 一张30w 的表花了1.7min
- BNGL 处。这里广播了右表,然后遍历左表进行 nest loop join,每秒钟几百条的速度在处理。
针对以上两点逐步优化,查看load 表的job,发现只有一个 task 在跑,单线程的,遂想到 jdbc 调参,在加载表的时候加大并发度。
JDBC 调优主要涉及到以下 4 个参数。numPartitions 用于指定最大分区数,后面三个字段分别用来指定分区字段及划分每个分区的参数。在org.apache.spark.sql.execution.datasources.jdbc.JDBCPartitioningInfo 中可以看到计算分区的 columnPartition 方法。
这里突然想到在自定义数据源时,也可以自定义分区方法。
| options | description |
|---|---|
| numPartitions | 最大分区数,最终的分区数并不一定是这个值,当 upperBpund-lowerBound<numPartitions时,最终的分区数为upperBpund-lowerBound,具体的分区计算逻辑可以从源码中看到 |
| partitionColumn | 指定分区字段,分区字段类型必须为数值和时间类型 |
| lowerBound | 分区下界 |
| upperBpund | 分区上界 |
修改加载代码如下
1 | val load_imapla:(String, String) => Dataset[Row] = (impala_url, table) => {spark.read |
继续查看执行情况,可以看到加载数据源任务的并发度为 32,job 的执行时长缩减到了1.1min,并没有优化太多,可能是分区不均匀导致的。
针对 BNLG,因为这里是非等值连接,默认必然是这样的执行计划,inner join 情况下是做 crossjoin 笛卡尔积,更慢。那么有没有办法转换为等值连接呢,我这里的连接条件是列表包含,那么其实可以先做一层预处理 explod 列表,做等值连接。这样 join 的执行计划就是 sortMergeJoin。修改 join 代码如下
1 | val b = load_imapla("xx", "UsersB") |
查看执行情况,已经没有了 BNLJ。最后整个 Job 的执行情况耗时1.9 min,之前BNLJ时一个多小时。