Elasticsearch 与 Hive 集成
前言
工作上存在将 Hive 上的数据刷到 ES 的场景,首先想到的是自己写程序读取 Hive 上的数据,经过业务逻辑处理在写回到 ES 上,不过请教了下,知道了 ES 本身已经可以和 Hive 集成。只需添加对应的 jar 包,在 hive 上建立与 ES 关联的外部表,即可使用 HQL 查询写入 ES 索引库。具体使用请见官方文档 ,本文只举个简单例子及介绍下主要的参数。
Elasticsearch 集成 Hive
elasticsearch-hadoop jar 包下载
去 maven 中央仓库上去搜对应的 jar 包就行,这里只需要注意 jar 包的版本要和 ES 版本相对应。查看 ES 版本,只需要访问 ${es_node}:9200 即可。下载链接
下载完成后,只需要进入 Hive ,输入以下命令即可,和添加 UDF jar 差不多。
1 | add jar ${your_path}/elasticsearch-hadoop-${version}.jar |
建立 Hive 外部表
建表语句如下,这里需要注意 Hive 中的数据类型与 ES 中的对应关系,具体对应列表可以查看 Apache Hive integration
1 | CREATE EXTERNAL TABLE es_warehouse.tblleadsaccesslog( |
建表执行完成并且没有错误,就可以使用 HQL 直接查询关联的 ods_lec_leads_accesslog 的 ES 索引库。
1 | select * from es_warehouse.tblleadsaccesslog limit 10; |
也可以通过 HQL 直接插入数据到 ES。
1 | insert into tblleadsaccesslog values('test', 'test', 'test', '1', '1', '1', 'test', '1'); |
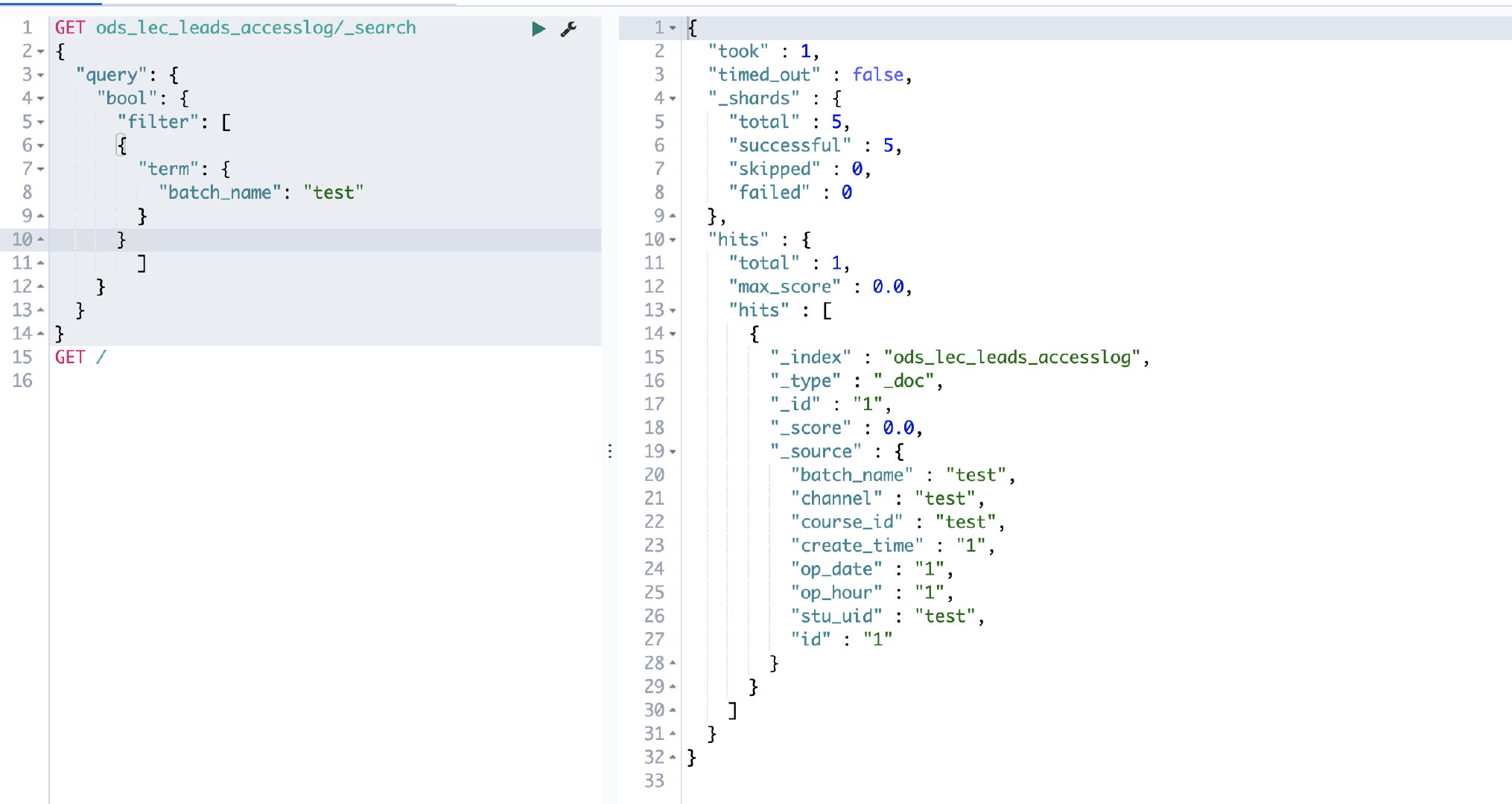
查询对应的 ES 索引库,可以查询到 batch_name 为 test 的数据。
ES 相关属性
更详细的可以直接参考官方文档 Configuration
| 属性名 | 释义 | 备注 |
|---|---|---|
| es.resource | es 索引库/表 | 也可以分别指定读,写的索引库 es.resource.read es.resource.write |
| es.nodes | es 节点 | |
| es.port | es 端口号 | |
| es.net.http.auth.pass | es 认证用户密码 | |
| es.net.http.auth.user | es 认证用户名 | |
| es.index.auto.create | 是否自动创建不存在的索引 | |
| es.mapping.id document | id 对应的字段 | |
| es.batch.write.refresh | 批量更新完成是否刷新索引库 | |
| es.write.operation | es 写时模式 | index,create,update,upsert |
| es.query | 默认读取 es 时的查询 DSL | |
| es.mapping.names | hive 与 es 字段之间的对应关系 |
配置属性都不太熟,尤其是刚使用 ES,还是建议先读一遍配置,不然就踩坑了。最近就踩了一个 case。在重新刷数据的时候,没有设置 es.write.operation 导致相同 doc_id 的数据被完全替换掉,而不是更新。这个参数默认是 index。
- index 新数据会追加,旧数据会直接覆盖
- create 追加数据,如果数据已经存在,抛出异常
- update 更新旧数据,如果旧数据不存在,抛出异常
- upsert 追加新数据,更新旧数据