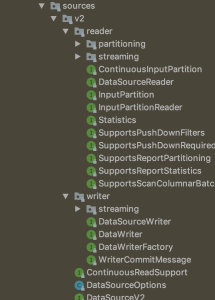
前面已经讲解了 Spark SQL 程序的入口,使用到的数据结构以及一些定义在上面的简单操作。那么我们工作中该如何将各种数据源中的数据转换成 Spark SQL 可以处理的数据结构进而进行各种计算呢?这就是本篇幅要讲解的 DataSource API(DataSource API 提供了读写各种数据源的 format,你甚至可以自定义 format 来连接外部数据源)。
在 Spark 中,连接处理各种形式的数据源是通过 DataSource API 中的 DataFrameReader 接口来实现的。你可以使用 SparkSession 来创建一个 DataFrameReader。
1 2 3 4 5 6 7 8 9 10 scala> val reader = spark.read reader: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader @65067 d37 DataFrameReader 将数据源中的数据通过合适的 format 转换成 Spark SQL 可以处理的 DataFrame 。Spark 2.0 提供了 textFile 方法,此时并不会返回 DataFrame ,而是 Dataset [String ]scala> reader.format("csv" ).load("people.csv" ) scala> reader.json.load("people.json" ) scala> reader.textFile("get-pip.py" ) res0: org.apache.spark.sql.Dataset [String ] = [value: string]
下面 DataFrameReader 常见的接口
Method
Description
Example
csv
从 CSV 文件或者DataSet[String] 中读取 CSV 格式数据
spark.read.csv("xxx.csv")
format
读取数据源的格式,允许自定义
spark.read.foramt("csv")
jdbc
通过 JDBC 连接
json
从 json 文件或者DataSet[String] 中读取 json 格式数据
spark.read.json("*.json")
load
从数据源加载数据
spark.read.foramt("csv").load("input_path")
option
设置加载数据源的一些可选项,比如不加载 CSV 的 header,指定分隔符等
`spark.read.format(“csv”).option(“delimiter”, “
options
接收 Map 来设置可选项
`spark.read.format(“csv”).options(Map(“delimiter” → “
orc
orc 格式文件 spark.read.orc(input_path)
parquet
parquet 格式文件,这也是 Spark 的默认 format 。可以通过 spark.sql.sources.default 更改
spark.read.parquet(input_path)
schema
读取文件时指定 schema,schema 的生成后面会讲解
spark.read.format("csv").schema(inferScheam)
text
读取文件,返回 DataFrame
textFile
读取文件,返回 Dataset[String]
tip:Spark read 数据并不会触发计算。
Spark load 的路径可以是目录,并且支持通配符,Spark 会自动递归查找到目录下的所有文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 spark.read.csv("/data/sa_cluster/etl/*/*.csv" ) ```` Spark 2.2 开始支持从 Dataset [String ] 中加载数据。大概会有这样的场景,对格式不统一的数据先加载成 Dataset [String ],然后按 Row 处理每行数据成标准格式,最后从 Dataset [String ] 中读取格式化的数据。```scala scala> val people = Seq ("Mike, 40" ).toDS people: org.apache.spark.sql.Dataset [String ] = [value: string] scala> spark.read.csv(people) res3: org.apache.spark.sql.DataFrame = [_c0: string, _c1: string] scala> spark.read.csv(people).show() +----+---+ | _c0|_c1| +----+---+ |Mike | 40 | +----+---+
tip:spark.readStream 用来读取流数据
1 2 scala> spark.readStream res5: org.apache.spark.sql.streaming.DataStreamReader = org.apache.spark.sql.streaming.DataStreamReader @45354715
DataFrameWriter 与 DataFrameReader 对应,将计算处理好的数据以各种数据格式存储。可以用处理好的 Dataset 直接创建。
1 2 3 4 5 6 7 8 9 scala> val writer = spark.range(5 ).write writer: org.apache.spark.sql.DataFrameWriter [Long ] = org.apache.spark.sql.DataFrameWriter @1131 fcfd DataFrameWriter 支持的 format 和 DataFrameReader 是一样的。当然默认 format 还是 parquet 文件。 详细的 API 可以去查看 org.apache.spark.sql.DataFrameWriter 的源代码。可以去读一下 save 方法。里面告诉了我们直接将存入 Hive 中是不允许的,最后的 save 的触发操作是由 runcommand 实现的。这里的一些逻辑我个人还没有搞清楚,仅仅是建议大家可以去读一下源代码。如果你想了解存储,actions 算子到底是如何触发计算,触发存储的,那么读源代码是一个很好的选择。 scala> writer.format("json" ).save("id" ) scala> writer.json("id" )
在今天之前,我只是看到过 V1 V2这样的字眼。并没有详细了解过。这里只作为一个引路人的角色。
先介绍几个概念
列裁剪: 过滤掉查询不需要使用到的列。就是这样子的啦,select id, name from table。
谓词下推 :将过滤过程尽可能的推到底层,最好数据源端,这样子在执行阶段数据计算量就会相应变少。举个极端的例子,如果数据在上层才过滤,那么从读取到 fliter 都要保持着全表才可以,这无疑加大了计算量和资源消耗,我们希望的是读取出来的数据就是已经过滤的。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 scala> val ds = spark.range(3 ).withColumn("idPlus" , $"id" + 1 ) ds: org.apache.spark.sql.DataFrame = [id: bigint, idPlus: bigint] scala> ds.select("idPlus" ).filter($"id" === 1 ).explain(true ) == Parsed Logical Plan == 'Filter ('id = 1 )+- Project [idPlus#6 L] +- Project [id#4 L, (id#4 L + cast(1 as bigint)) AS idPlus#6 L] +- Range (0 , 3 , step=1 , splits=Some (4 )) == Analyzed Logical Plan == idPlus: bigint Project [idPlus#6 L]+- Filter (id#4 L = cast(1 as bigint)) +- Project [idPlus#6 L, id#4 L] +- Project [id#4 L, (id#4 L + cast(1 as bigint)) AS idPlus#6 L] +- Range (0 , 3 , step=1 , splits=Some (4 )) == Optimized Logical Plan == Project [(id#4 L + 1 ) AS idPlus#6 L]+- Filter (id#4 L = 1 ) +- Range (0 , 3 , step=1 , splits=Some (4 )) == Physical Plan == *(1 ) Project [(id#4 L + 1 ) AS idPlus#6 L] +- *(1 ) Filter (id#4 L = 1 ) +- *(1 ) Range (0 , 3 , step=1 , splits=4 )
Spark 1.3 为了提供一个统一的数据源 API 开始引入 DataSource V1。有了 DataSource V1,我们可以很方便的读取各种来源的数据,而且 Spark 使用 SQL 组件的一些优化引擎对数据源的读取进行优化,比如列裁剪、过滤下推等等。 你可以在 org.apache.spark.sql.source 中查看源代码。Spark SQL 的谓词下推是根据某些规则来的,并不是任何谓词任何条件下都会下推。
既然 Datasource API 可以满足我们绝大多数的需求,那为什么又出来个 DataSource v2。主要是由于以下几点因素。
Datasource API v1 依赖于一些上层 API,如 SqlContext 和 DataFrame。我们知道 Spark 2.x 里面 SqlContext 被 SparkSession 代替,DataFrame 被统一到 Dataset。上层 API 在不断更新发展,在 Datasource API v1 中确没有什么体现。
这里直接用一个网上 DataSource v2 API 读取 MySQL 数据的例子,来看看如何自定义你的 format,实现你的读写逻辑,谓词下推。
通过 DataSource API v2 的 ReadSupport 接口来实现自定义数据源 reader,这里是读取 Mysql,如果是写 Mysql 需要 WriteSupport
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mysqlReaderimport org.apache.spark.sql.sources.v2.reader.DataSourceReader import org.apache.spark.sql.sources.v2.{DataSourceOptions , DataSourceV2 , ReadSupport }import scala.collection.JavaConverters ._class DefaultSource extends DataSourceV2 with ReadSupport override def createReader DataSourceOptions ): DataSourceReader = { MySQLSourceReader (options.asMap().asScala.toMap) } }
通过 DatasourceReader 具体实现读操作,读取的 scheam,列裁剪,支持的谓词下推,分区信息都可以在这里重写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 package mysqlReaderimport java.utilimport org.apache.spark.sql.catalyst.InternalRow import org.apache.spark.sql.execution.datasources.jdbc.{JDBCOptions , JDBCRDD }import org.apache.spark.sql.sources.v2.reader.{DataSourceReader , InputPartition , SupportsPushDownFilters , SupportsPushDownRequiredColumns }import org.apache.spark.sql.sources.{EqualTo , Filter , GreaterThan , IsNotNull }import org.apache.spark.sql.types.StructType import scala.collection.JavaConverters ._import scala.collection.mutable.ArrayBuffer case class MySQLSourceReader (options: Map [String , String ] ) extends DataSourceReader with SupportsPushDownFilters with SupportsPushDownRequiredColumns { val supportedFilters: ArrayBuffer [Filter ] = ArrayBuffer [Filter ]() var requiredSchema: StructType = { val jdbcOptions = new JDBCOptions (options) JDBCRDD .resolveTable(jdbcOptions) } override def readSchema StructType = { requiredSchema } override def planInputPartitions List [InputPartition [InternalRow ]] = { List [InputPartition [InternalRow ]](MySQLInputPartition (requiredSchema, supportedFilters.toArray, options)).asJava } override def pushFilters Array [Filter ]): Array [Filter ] = { if (filters.isEmpty) { return filters } val unsupportedFilters = ArrayBuffer [Filter ]() filters foreach { case f: EqualTo => supportedFilters += f case f: GreaterThan => supportedFilters += f case f: IsNotNull => supportedFilters += f case f@_ => unsupportedFilters += f } unsupportedFilters.toArray } override def pushedFilters Array [Filter ] = supportedFilters.toArray override def pruneColumns StructType ): Unit = { this .requiredSchema = requiredSchema } }
InputPartitionReader 实现具体的分区读取操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 package mysqlReaderimport java.sql.{DriverManager , ResultSet }import org.apache.spark.sql.catalyst.InternalRow import org.apache.spark.sql.catalyst.util.DateTimeUtils import org.apache.spark.sql.jdbc.JdbcDialects import org.apache.spark.sql.sources.v2.reader.{InputPartition , InputPartitionReader }import org.apache.spark.sql.sources.{EqualTo , Filter , GreaterThan , IsNotNull }import org.apache.spark.sql.types._import org.apache.spark.unsafe.types.UTF8String case class MySQLInputPartition (requiredSchema: StructType , pushed: Array [Filter ], options: Map [String , String ] ) extends InputPartition [InternalRow ] { override def createPartitionReader InputPartitionReader [InternalRow ] = { MySQLInputPartitionReader (requiredSchema, pushed, options) } } case class MySQLInputPartitionReader (requiredSchema: StructType , pushed: Array [Filter ], options: Map [String , String ] ) extends InputPartitionReader [InternalRow ] { val tableName = options("dbtable" ) val driver = options("driver" ) val url = options("url" ) def initSQL val selected = if (requiredSchema.isEmpty) "1" else requiredSchema.fieldNames.mkString("," ) if (pushed.nonEmpty) { val dialect = JdbcDialects .get(url) val filter = pushed.map { case EqualTo (attr, value) => s"${dialect.quoteIdentifier(attr)} = ${dialect.compileValue(value)} " case GreaterThan (attr, value) => s"${dialect.quoteIdentifier(attr)} > ${dialect.compileValue(value)} " case IsNotNull (attr) => s"${dialect.quoteIdentifier(attr)} IS NOT NULL" }.mkString(" AND " ) s"select $selected from $tableName where $filter " } else { s"select $selected from $tableName " } } val rs: ResultSet = { Class .forName(driver) val conn = DriverManager .getConnection(url) println(initSQL) val stmt = conn.prepareStatement(initSQL, ResultSet .TYPE_FORWARD_ONLY , ResultSet .CONCUR_READ_ONLY ) stmt.setFetchSize(1000 ) stmt.executeQuery() } override def next Boolean = rs.next() override def get InternalRow = { InternalRow (requiredSchema.fields.zipWithIndex.map { element => element._1.dataType match { case IntegerType => rs.getInt(element._2 + 1 ) case LongType => rs.getLong(element._2 + 1 ) case StringType => UTF8String .fromString(rs.getString(element._2 + 1 )) case e: DecimalType => val d = rs.getBigDecimal(element._2 + 1 ) Decimal (d, d.precision, d.scale) case TimestampType => val t = rs.getTimestamp(element._2 + 1 ) DateTimeUtils .fromJavaTimestamp(t) } }: _*) } override def close Unit = rs.close() }
使用自定义的 format 读取 Mysql 数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import org.apache.spark.sql.SparkSession object test def main Array [String ]): Unit = { val spark = SparkSession .builder().appName("MySQL" ).master("local[*]" ).getOrCreate() import spark.implicits._ spark.read .format("mysqlReader" ) .option("url" , "jdbc:mysql://127.0.0.1:3306/fangtianxia?user=root&password=123456789" ) .option("dbtable" , "newfangdetail" ) .option("driver" , "com.mysql.jdbc.Driver" ) .load() .selectExpr("url_name" , "score" ) .filter($"url_name" .equalTo("121119" ) && $"score" >= "3.6" ) .explain(true ) } }
执行后,可以看到执行的物理计划如下,equalTo 被下推到数据源端,而 >= 没有被下推,因为我们自定义的 pushedFilter 中不支持 >= 下推
1 2 3 4 == Physical Plan == *(1) Project [url_name#3, score#11] +- *(1) Filter (score#11 >= 3.6) +- *(1) ScanV2 DefaultSource[url_name#3, score#11] (Filters: [isnotnull(url_name#3), isnotnull(score#11), (url_name#3 = 121119)], Options: [dbtable=newfangdetail,driver=com.mysql.jdbc.Driver,url=*********(redacted),paths=[]])
一文理解 Apache Spark DataSource V2 诞生背景及入门实战