关于数开的一些问题
前言
emnn,先把问题罗列一下,周末梳理梳理。借用了很多文章,侵删
问题
Spark sortmergeshuffle 和 hashshuffle 的实现和区别,bypass 机制是什么?可以看下这篇文章 Spark–Spark Shuffle发展史及调优方法
Scala 的高阶函数 map reduce fold,这些是怎么实现的呢?
像 fold 函数,一般都是赋一个初始值,然后交给操作函数,操作函数的值作为下一次的初始值。这其实也是一种思想,告诉编译器做什么,而不是告诉编译器怎么做。java 多线程 廖雪峰Java教程
生产者-消费者模型,互斥锁和信号量
生产者-消费者模型JVM 模块 和 内存模型
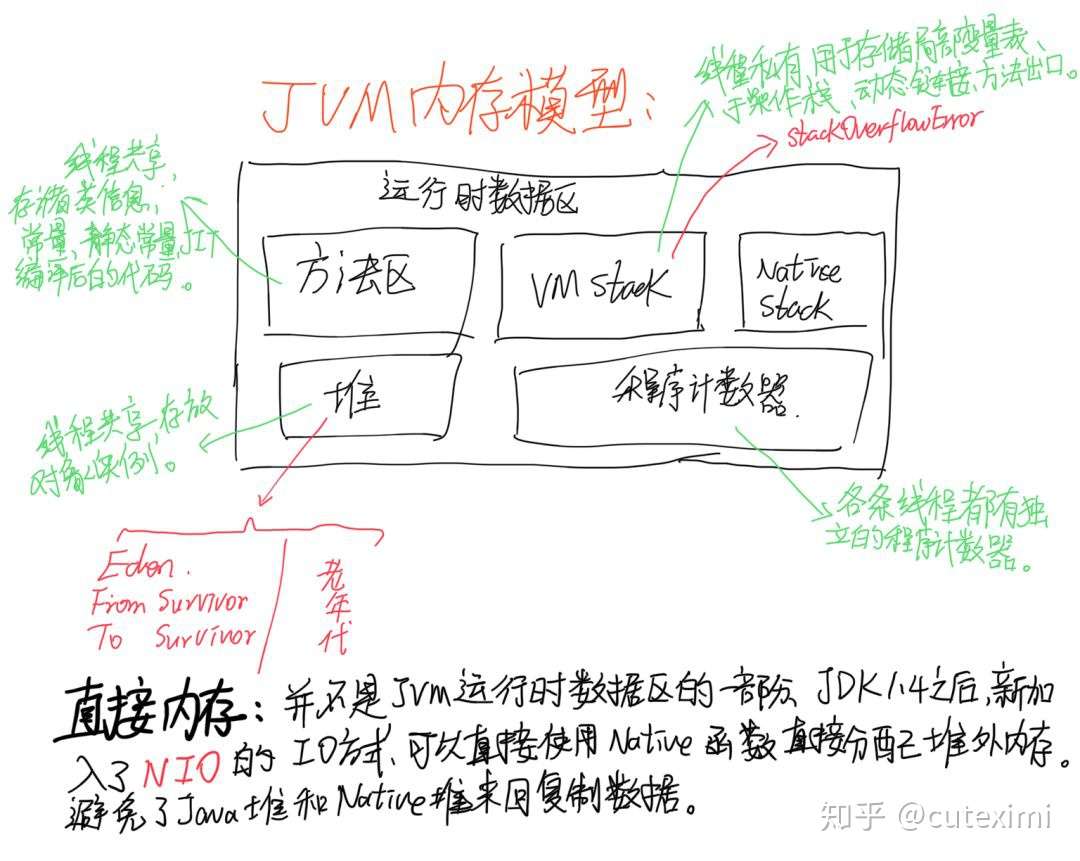
Flink watermark trigger,trigger 是怎么实现的?迟到数据是怎么处理的?watermark 到底是做什么的
watermark 更像是为了控制状态无限制的增长,会告诉框架什么时间结果不会在变化。关于流处理的一些概念,曾经读过 DataFlowModal(ps:忘光了。。)。这里推荐一篇文章 由Dataflow模型聊Flink和SparkSpark StructStreaming
推荐多度几遍官方文档,Spark 3.x 的重点好像在 ML,contionus processing 发展的比较慢。该如何理解 Flink
由Dataflow模型聊Flink和SparkFlink 架构中重要的模块
官方文档Distributed Runtime Environment列裁剪,谓词下推,常量累加
一条 SQL 在 Apache Spark 之旅(中)漏斗怎么实现
join 或者 UDAFRDD 的特性,五个属性是什么
只读,并行,分布式,粗粒度,可以直接查看源码,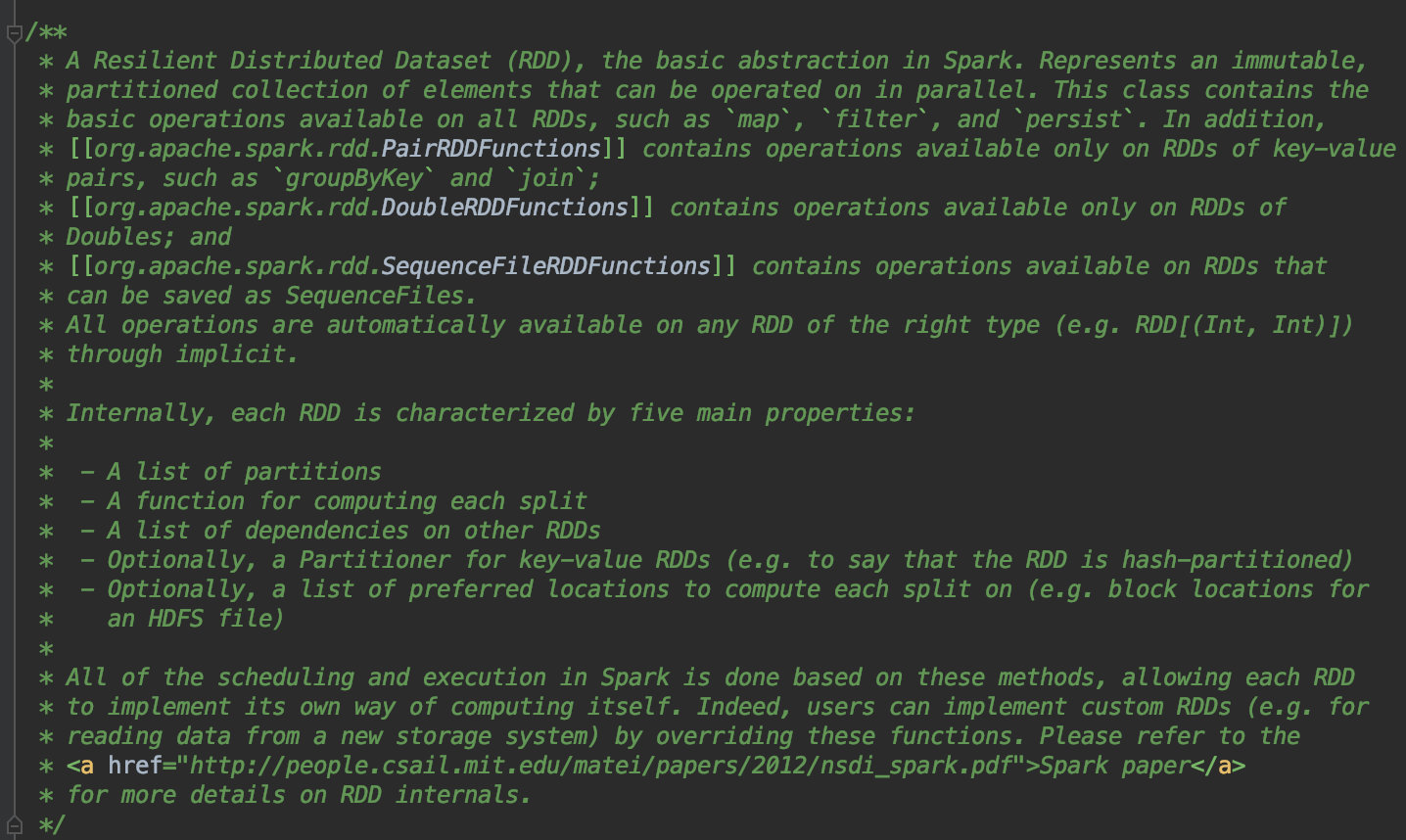
RDD 之间的宽窄依赖是什么?有什么区别
窄依赖,即子RDD依赖于父RDD中固定的Partition。NarrowDependency 分为 OneToOneDependency 和 RangeDependency两种。
宽依赖,shuffle 依赖,即子 RDD 对父 RDD 中的所有 Partition 都有依赖。unresolverelation plan 和 logiacl plan 的区别,unresolverelation plan 是由谁解析的,怎么解析的?
一条 SQL 在 Apache Spark 之旅(中),这几篇文章详细讲解了 DSL 或者 SQL 在 Spark 中的历程,不得不感叹框架为我们做了太多太多的事情,当然明白执行过程,也方便我们查看 DAG,读懂各种执行计划。spark catalyst 语法分析优化,spark catayast 对语法分析树是通过什么规则来优化的
深入研究Spark SQL的Catalyst优化器(原创翻译)CBO RBO 的具体实现,有哪种规则
Spark SQL / Catalyst 内部原理 与 RBO
https://blog.csdn.net/Habren/article/details/82847908Spark 作业的提交过程,Spark SQL 在 spark 内部是怎么执行的?
一条 SQL 在 Apache Spark 之旅(中)WholeStageCodeGen 是用来做什么的
生成类似手写效果代码,为了提高运行效率。spark on hive
Hive TablesSpark 统一内存模型
- spark.memory
- executor memory
- storage memory
- user.mermory
- reverse memory
spark.memory 与 user.memory 默认比例为 0.6 0.4。executor memory与storage memory 属于动态分配。但是观察web UI 发现频繁 GC 的话,还是要调高 executor memory的占用比例。reverse memory 300M。
- spark.memory
虚拟内存与磁盘缓存
磁盘与内存对数据仓库的理解
数据仓库与传统数仓到底有啥区别?数据中台的概念。用户态内核态,什么情况会造成用户态和内核态的切换,有哪些异常
zero_copysql join 中 on 的作用是什么,不加 on 和加 on 有什么区别
指定关联条件Scala 的不可变性与函数组合子 ,不可变性的优势
emnn,这个原先看过,趁着最近在读 Scala 实用指南,在熟悉一遍