Hadoop是什么
Hadoop
Hadoop 是海量数据分布式存储和计算框架,脱身于 Google 三大论文。现在我们常说的 Hadoop 往往指的是 Hadoop 生态圈。
Hadoop 1.x 与 2.x
Hadoop 1.x 中的 Map Reduce用于资源调度和分布式计算。Hadoop 2.x 引入了 YARN 用于资源调度,Map Reduce 只用于分布式计算。相当于对解耦合。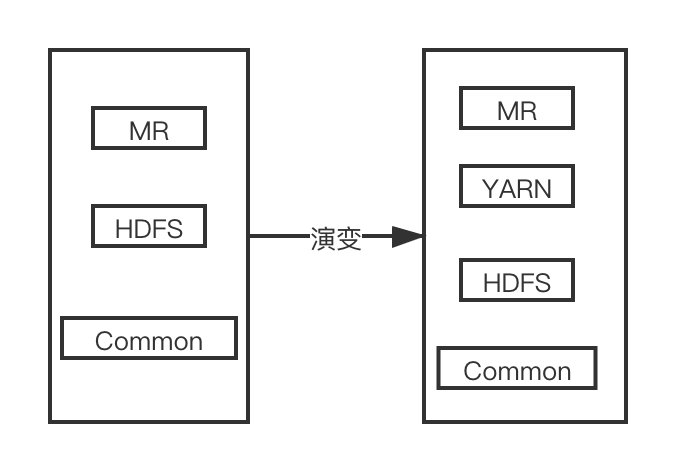
HDFS
HDFS 分布式文件存储系统。其主要组成分为 NameNode, DataNode 和 Secondary NameNode。
NameNode:元数据节点,元数据也就是表述数据的数据,比如文件的存放位置,大小等等。元数据一般驻留在内存中,所以大量的碎片文件可能会导致 NameNode 的 OOM。这是一个需要注意的地方。另外 NameNode 执行格式化,重启的时候,都要考虑清楚对 DataNode 的影响。
DataNode:数据节点,真正存放数据的节点。
Secondary NameNode:NameNode 的辅助接点,类似 CheckPoint 的作用。NmaeNode 启动时会生成一个系统快照,启动之后的文件改动信息会记录到日志当中。当重启时,会将上一次的快照和改动日志进行合并生成一个新的系统快照。通过这样来保证每次启动时系统快照都是最新的。但是 NameNode 不能经常重启,改动日志会变的比较大,如果下次重启 NameNode ,改动合并过程也可能导致重启过慢。这时候就需要 Secondary NameNode 了,它会定时查询改动日志,合并 NmaeNode 启动时的快照,在传回 NmaeNode。
YARN
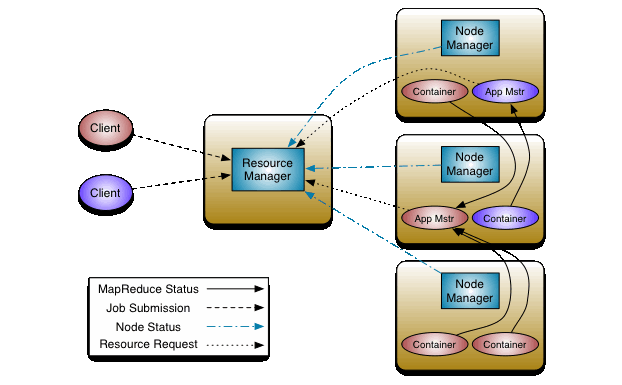
上面这张图展现了 YARN Appliaction 的调度运行过程。
- 客户端提交任务
- Resource Manager,接收 Job 提交的请求,分配资源
- NodeManager 监控该节点的整体资源状态,并像 Resource Manager 汇报。
- 启动 ApplicationMastr,ApplicationMastr 协调管理制定 Job 运行的 Container。
后记
个人接触大数据已经半年多了,但是仅局限于 Spark SQL。其他东西用的还是蛮少的,甚至不知道东西该用在什么地方。Apache 这一套东西到底是怎么互相结合的,没有一个层次的概念。这里根据这几天看到的记录一下。
数据采集层:结构化数据, 半结构化数据,非结构化数据
数据传输层:Sqoop处理结构化数据,比如 MySQL 等,Flume日志收集,Kfaka 收集非结构化数据消息直接进行分析,比如视频,音频等。
数据存储层:HDFS,HBase等。
元数据管理层:atlas 管理整体的元数据,数据血缘追溯
数据分析计算层:Spark + Flink,离线计算和实时计算,而且提供了 MLLib 用于数据挖掘和机器学习。
任务调度层:Azkaban 任务调度
配置管理层:Zookeeper 管理整体配置,节点命名等。
可视化层:kylin,clickhouse 分析结果可视化,报表开发,还有 Doris