循序渐进学 Spark
前言
讲一下我个人是从哪些方面来学习 Spark SQL 的?一句话就是自顶向下,逐步下探。
整体架构
类似于大多数的大数据处理框架,宏观上 Spark JOB 的提交运行主要和三种角色有关,客户端,集群管理器,工作节点。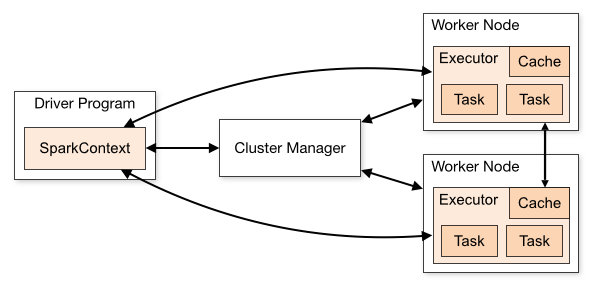
Cluster Manager:在 standalone 模式中即为 Master 主节点,控制整个集群,监控 worker。在 YARN 模式中为资源管理器。
Worker节点:从节点,负责控制计算节点,启动 Executor 或者 Driver。
Driver: 运行 Application 的 main() 函数。
Executor:执行器,某个 Application 运行在 worker node 上的一个进程。运行 task 和 管理运行过程中的数据存储
Spark 应用程序作为独立的进程集运行在集群上,通过 Driver Program 中的 SparkContext 对象来进行调度。一旦连接上 Cluster Manager(YARN,Spark 自带的 Standalone Cluster),Spark 就会在对应的 Worker 上启动 executor 进程用于计算和存储应用程序运行所需要的数据。接着你的应用程序代码会被发送到各个 executor 。SparkContext 会调度生成 task 在 executor 进程中执行。
模块
一个 Spark SQL Appliaction 是怎么被提交运行的呢,其中主要涉及到哪些模块呢。
一个 Spark 应用程序运行,首先会经过 BlockManager 和 BroadCastManager 做一些 Hadoop 配置或者变量的广播,然后由 DAGScheduler 将任务转换为 RDD 并组织成 DAG,DAG 还将被划分为不同的 Stage。最后由TaskScheduler 借助 ActorSystem 将任务提交给集群管理器(Cluster Manager)。如果存在 shuffle 过程,其存管理主要会涉及到 ShuffleBlockManager 。集群管理器分配资源,对应的 Worker 节点上启动 Executor 进程运行 task。
可以通过一个 action 算子的触发去读源码,看这些模块是如何实现的。
SQL 执行
一条 SQL 的执行会经过哪些阶段,其实用过 MySQL 就知道,解析执行计划,分析执行计划,优化执行计划,物理执行计划,代码生成。SQL on Hadoop 其实也是一样的。
以下是一个典型执行计划的示例
1 | == Parsed Logical Plan == |
解析执行计划
Spark SQL Parser 负责解析执行计划到 unresolved plan,这个阶段解析出来的执行计化可能没有数据源来自哪里,字段属性等信息,比如 unsolverelation分析执行计划
Spark SQL Analysr 利用 catlog 元数据信息将 unresolved plan 依据一些 rule 生成 Analyzed logical plan,其实就是一颗完整的 SQL 语法树,到这一步其实我们已经知道了数据来自哪里,属性等元数据信息。优化执行计划
Catalyst Optimization 负责优化执行计划。主要分为 RBO 和 CBO,默认是关闭了 CBO。常见的 RBO 有谓词下推,列裁剪,常量替换,常量累加。这一部其实做的就是上步分析过程生成这棵 SQL 语法树。
如果看过执行计划,其实可以经常看到谓词下推,比如 filiter 算子被下推到数据源端。
为什么默认关闭了 CBO,个人的理解是,RBO 已经满足了大部分效率方面的需求,并且 CBO 本身也需要收集统计信息进行代价计算,这也是有代价的。故应该根据自己的场景来判断是否开启。物理执行计划
经过 RBO,CBO 之后,会选出相对最优的执行计划作为最终执行的计划。代码生成
物理执行计划生成后,需要通过代码生成阶段生成类似手写代码运行计算。这也是在 DAG 图里常见的 WholeStageCodegen
DAG 图
物理执行计划的展现,更直观。这里只提几个问题,
- 通过物理执行图,你知道是怎么被切分 stage 的吗?
- Shuffle Dependency 是怎么被 attach 到执行图当中的
- 执行图中的各种类型的 RDD 到底是什么意思,像 MapPartitionRDD 等,什么情况下会生成他?