Actions - Trigger real calculations
前言
你可能已经知道 action 会触发提交 Spark 作业,开始进行真正的计算。那么 action 到底是什么,又是如何触发计算的呢?希望本篇可以带你了解这些东西。
Action 算子是如何触发计算的?
这里可以简单看下源码,首先进入到 spark-core 中的 org.apache.spark.rdd.RDD.scala。这个文件是干啥的嘞。可以直接看注释,RDD.scala 声明了什么是 RDD,已经定义在一些 RDD 上的算子操作,spark 调度和执行是否完成都依赖这个文件里定义的方法。因此,可以在这里找到一个任意 action 算子进行分析。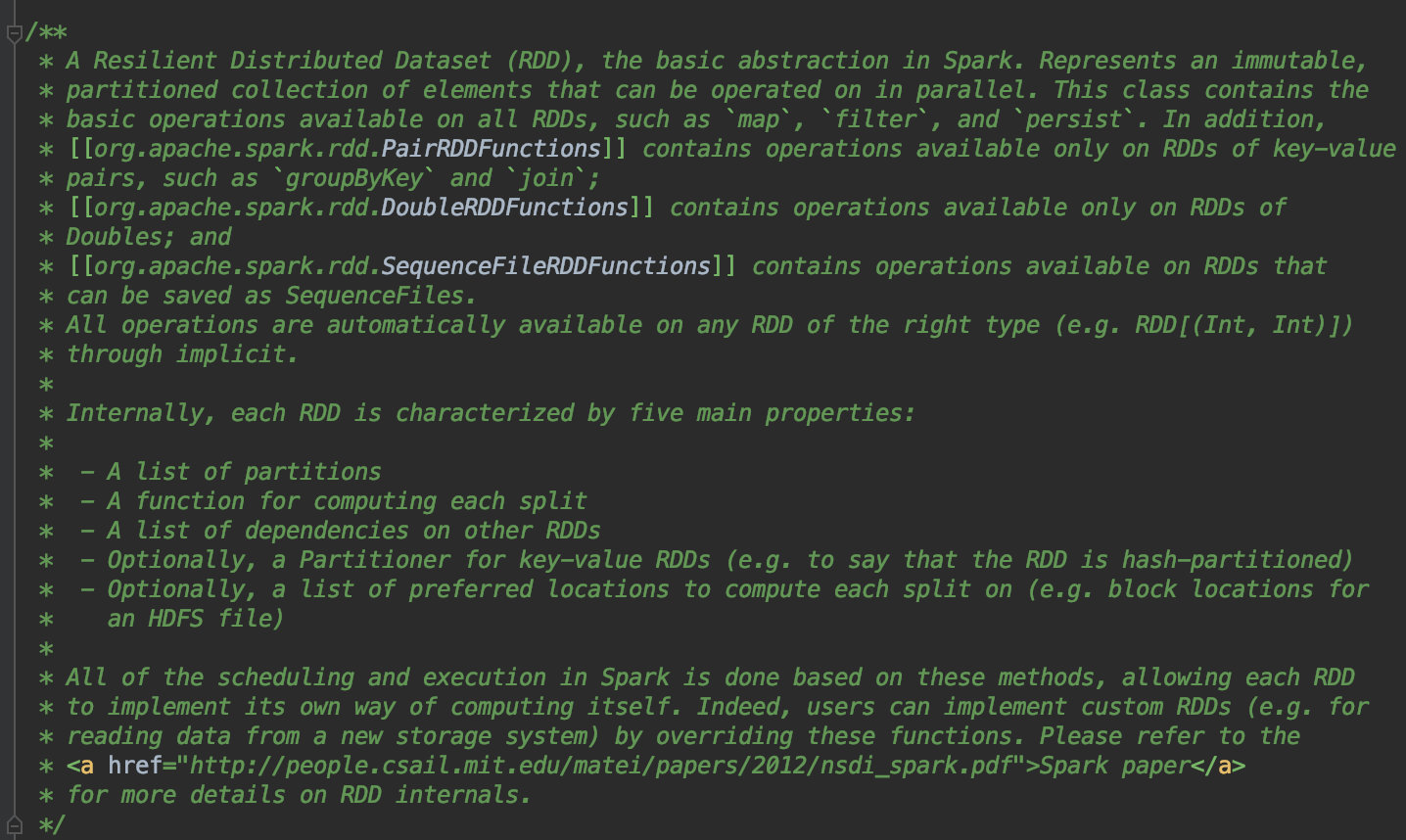
这里可以看下 collect 算子。它的功能就是将各个分区的结果数据都拉取到 driver 端,并将结果放到 Array 里面。结果是通过 runJob 执行拿到的。
点开 runJob 方法,其参数是 RDD 以及在 RDD 每个分区上上执行的方法。其内部执行的 runJob 就是下方重载的 runJob,多了一个 RDD 分区的参数。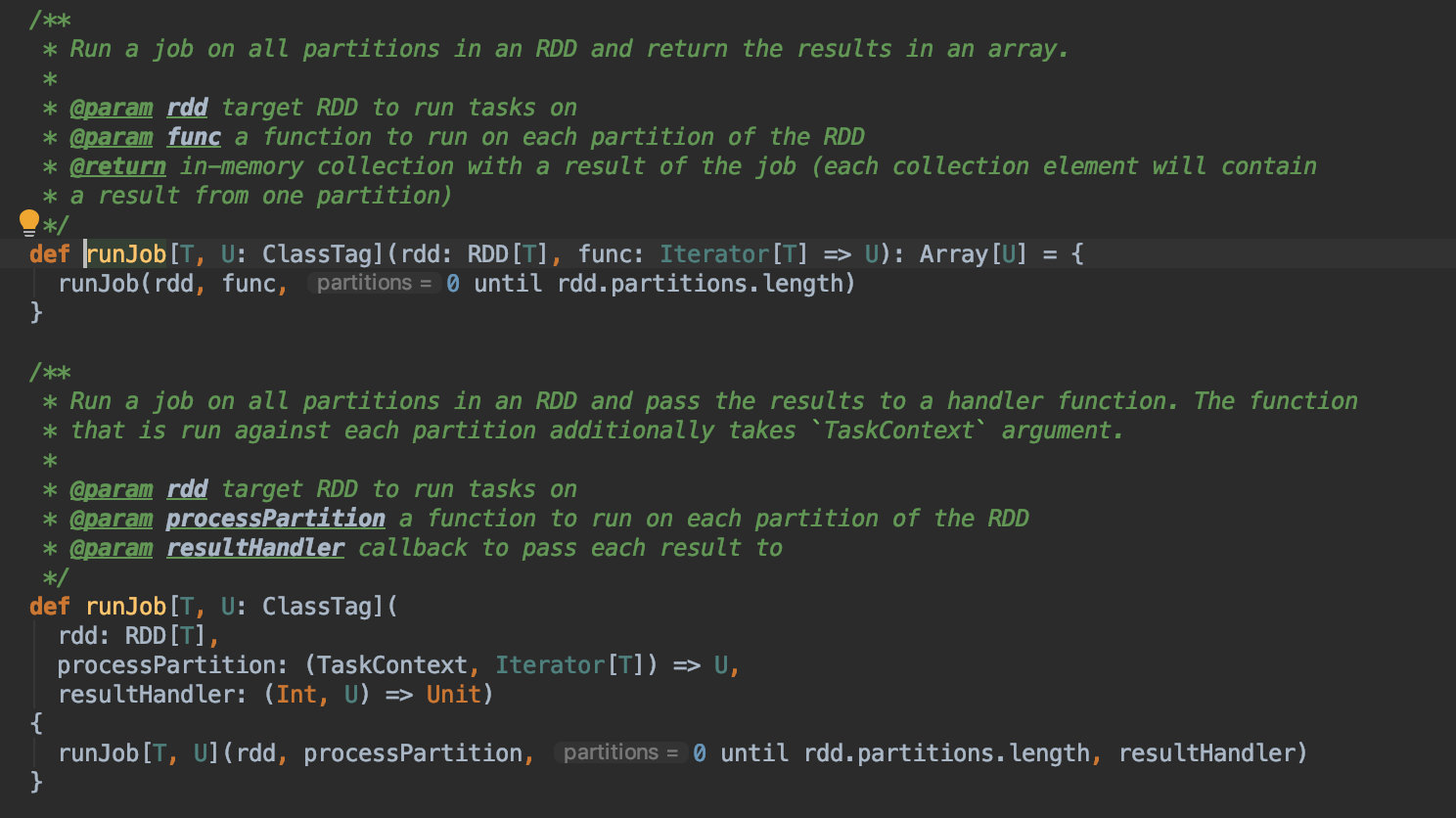
内部又是一个重载的 runJob,通过注释可以看到这个方法是 Spark 中所有 action 最终执行 runJob 的地方。这里先判断 SparkContext 是否存活,如果存活,将这个算子交给 DAG Scheduler,完成后会做 in memory 的 checkpoint,应该是为了任务失败自动恢复。前面说过 DAG Scheduler 是用来构建 DAG 图,划分 Stage,分发 task 的。emnn,下面就是这些逻辑了。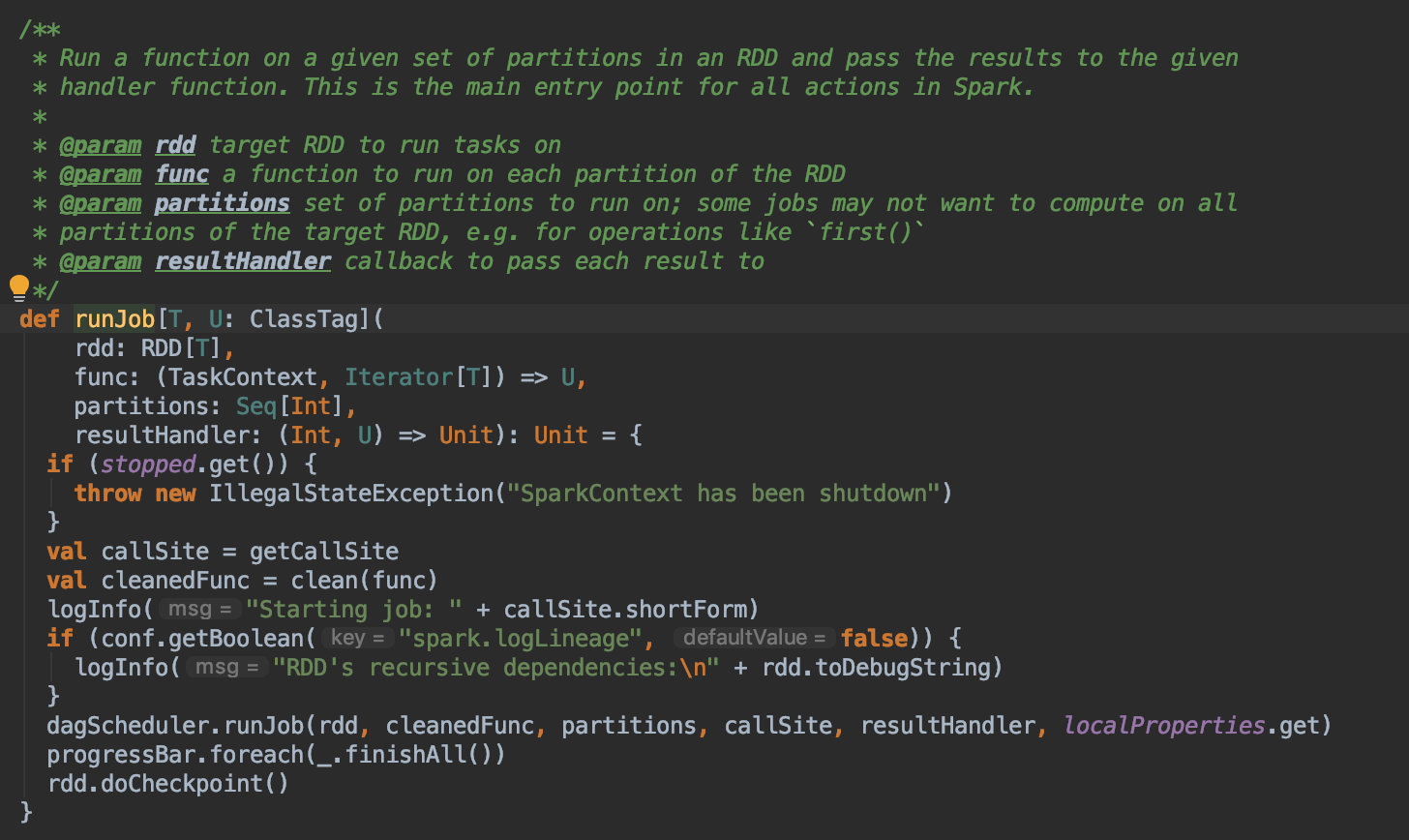
点进 DAG Scheduler 的 runJob,此处是提交 action job 到 Scheduler,并阻塞直到 Job 完成,如果 Job 执行失败,会抛出错误。
点进 submitJob,submitJob 首先会检查分区是否存在,如果存在,赋给该 job 一个 jobId,用以区分不同的 Job。如果分区数为0,返回一个 JobWaiter,这里涉及到 Scala future,promise 的知识。不太懂 。如果分区数大于 0,把该 job 发送到 eventProcessLoop。
这里的 eventProcessLoop 就是 DAGSchedulerEventProcessLoop,Job 被发送到 DAGScheduler 的事件处理循环去处理。上面的 post 的方法是 EventLoop 实现的。DAGSchedulerEventProcessLoop 继承了 EventLoop。EventLoop 的 doOnReceive 方法里是事件触发的执行逻辑。 这里直接看 DAGSchedulerEventProcessLoop 里的实现。上一步 submitJob 中 post 的是 JobSubmitted。这里会对应执行里面的 handleJobSubmitted 方法。同样的可以点进去看看,里面是划分 stage 的具体逻辑。


到这里,基本上可以看到 action 触发计算的逻辑。action → runJob → DAGScheduler runJob → submitJob → DAGSchedulerEventProcessLoop → handleJobSubmitted → createShuffleMapStage。
Action
根据源码里标识的函数签名,action 分为 basic action 和 action。但是到底有啥区别,这个还没搞清楚。
1 | Basic actions are a group of operators (methods) of the Dataset API for transforming a Dataset into a session-scoped or global temporary view and other basic actions |
这里介绍下常见的 action 算子,我们也很容易想到,打印,输出到各种数据存储这些都是 action
| Method | Description | Example |
|---|---|---|
| cache/persist | 缓存或者持久化,区别是默认的缓存级别不一样 | |
| checkpoint | 检查点,可用于恢复 Spark Job 的执行, | |
| columns | 返回包含所有列名的序列 | |
| createGlobalTempView | 创建临时视图,创建视图的方法有好几个,可以去自己查下,区别是视图的声明周期不一样,和 SparkSession 有关 | |
| explain | 输出详细的执行计划 | |
| isEmpty | 数据集是否为空 | |
| printSchema | 打印数据集的 schema | |
| rdd | 转换为 RDD | |
| write | DataFrameWriter | |
| toDF | ||
| schema | ||
| collect | 收集计算结果到 driver 端,返回包含结果的Array | |
| first | ||
| show | 展示几条数据,常用的参数就是 numRows,和 truncate,分别是显示多少行,是否每列显示完整 |