doris实时数据摄入测试
前言
观察 flink-doris-connector 和 RoutineLoad 的数据摄入情况,包括 kafka消费速率、doris 集群情况、doris 数据导入速率、各种调参造成的性能波动、不同 doris 表数据模型以及数据处理语义对导入性能的影响。
性能测试
以下测试均为从 earliest 消费同一测试 topic(测试流量维持在 4w qps 左右,晚高峰在 8w qps。),逻辑是简单的 source → map → sink,即读取 kafka 数据进行简单的字段提取后就发往 doris。暂时忽略掉不同时间点 source 数据流量的差异。
初始 Flink 资源:
| slot | TM | JM Memory | TM Memory |
|---|---|---|---|
| 3 | 3 | 2048 | 2048 |
需要观测的指标:
- Kafka Topic 的写入及消费情况。
- Flink 任务的内存、cpu 使用,checkpoint的完成情况及整体的吞吐。
- Doris 集群 CPU ,内存,磁盘,网络 IO的情况。
- Doris 表的数据摄入速率。
- Doris 表后端 compaction 进程对摄入的影响。
针对每一种表模型的测试步骤:
- 初始资源运行,观察所有相关的监控。
- 单独调整 slot,翻倍,观察任务情况。
- 单独调整内存,翻倍,观察任务情况。
- 根据 2,3步任务吞吐量是否线性增长,混合调整 slot 和内存,验证想法。
- 根据数据大小以及 kafka 写入 QPS预估调整 sink.buffer.* 参数是否会有作用,如果有作用,调整之,观察任务吞吐量。
- 根据最终确定较优参数,启动测试任务运行观察 1~2 天。
- 调整数据处理语义到 extractly-once,再次启动测试任务运行观察 1~2 天。
duplicate 表
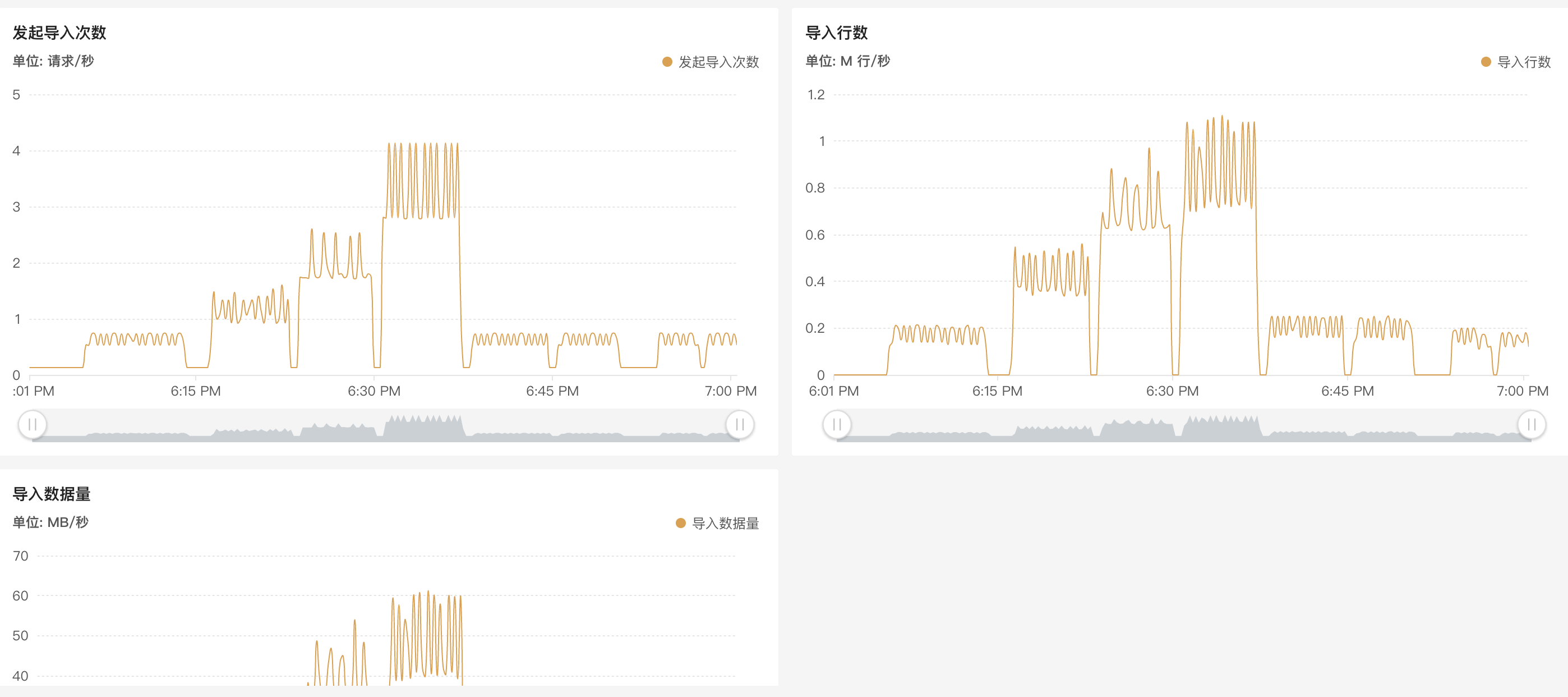
新建 duplicate 表 imp_flow_dup_small_test,三列数据,单条数据大小为 66 bytes。。测试导入。18:06 ~ 18:40 分别以 3,6,12,20 个slot 启动任务,整个任务的吞吐分别为 18w/s,40w/s,73w/s,86w/s,基本呈线性增长。18:40 ~ 18:50 调整回 3个 slot,分别以 4096,8192 内存运行,吞吐量无明显变化,20w/s 左右。
 |
 |
 |
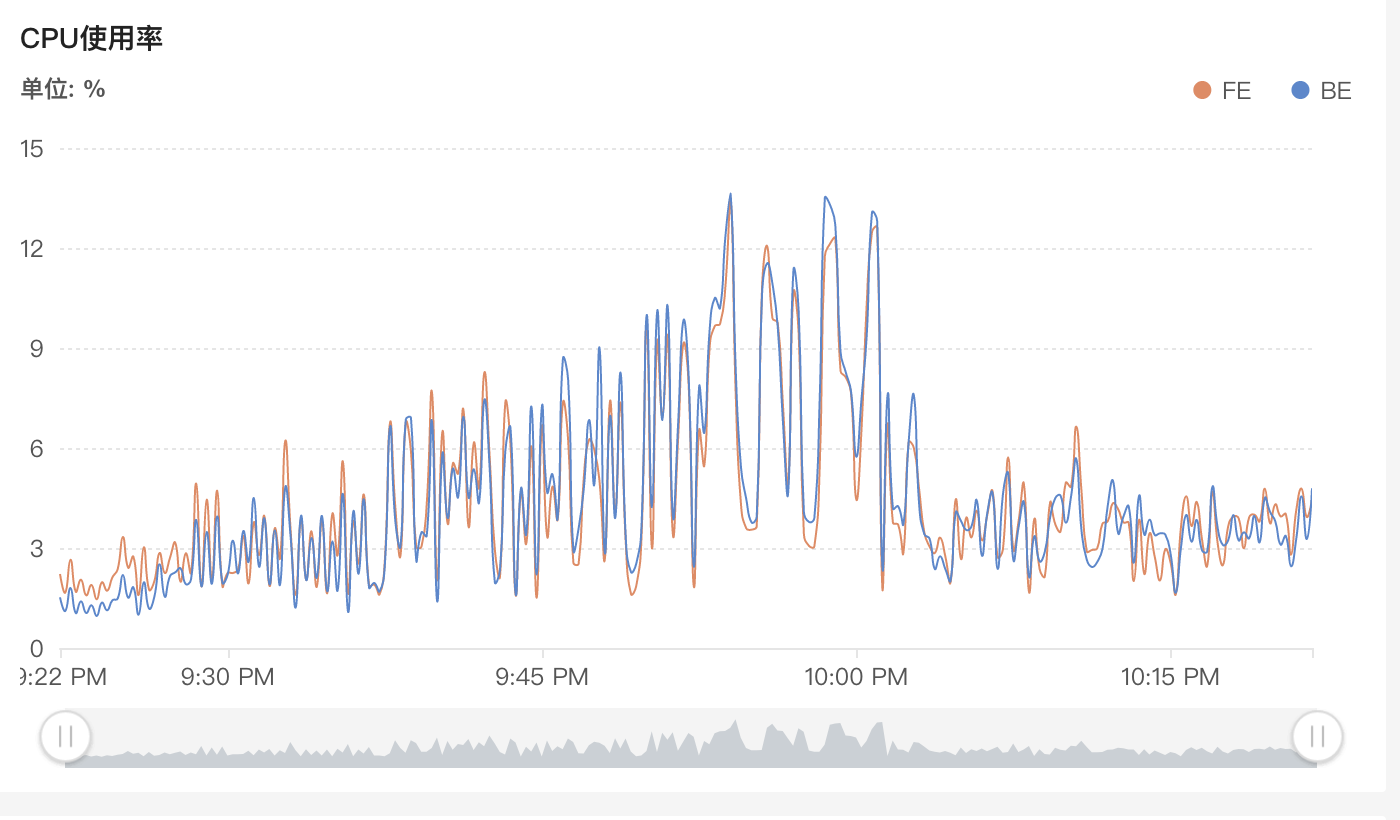
新建 duplicate 表 imp_flow_dup_big_test,五十列左右数据,单条数据 855 bytes。测试导入。21:30 ~ 22:04 分别以 3,6,12,20 个slot 启动任务,吞吐量分别为 10w/s,23w/s,43w/s,43w/s,在并发达到 12 个及以上后,可以看到处理速度陡降的现象,这是任务挂掉了,触发了 close index channel failed 和 index channel has intoleralbe failure,此时需要关注下集群表数据版本合并情况。
22:04 ~ 22:15 以 3个slot,内存分别为 4096,8192 启动任务,处理速度 11w/s,有 5% ~ 10% 的增加。
22:15 ~ 22:20 更改 flush_interval=1000ms,可以看到没啥作用,整个任务的吞吐没啥变化,另外还有个评估标准,观察导入次数和导入函数,可以看到在导入次数翻倍的情况下,吞吐量仍然没有变化,说明调整没啥作用,可以通过观察导入监控,反复修改参数测试出来单次 stream load 最大的处理量。
 |
 |
 |
agg 表
新建 agg 表 imp_flow_agg_small_test,key 列 5 个,一个bitmap 列,一个 HLL 列,一个 SUM 列,单条数据 158 bytes 左右。测试导入。2021-12-05 10:39 ~ 2021-12-05 11:20。任务每秒吞吐量在 16w 左右,随 slot 线性增长。
 |
 |
 |
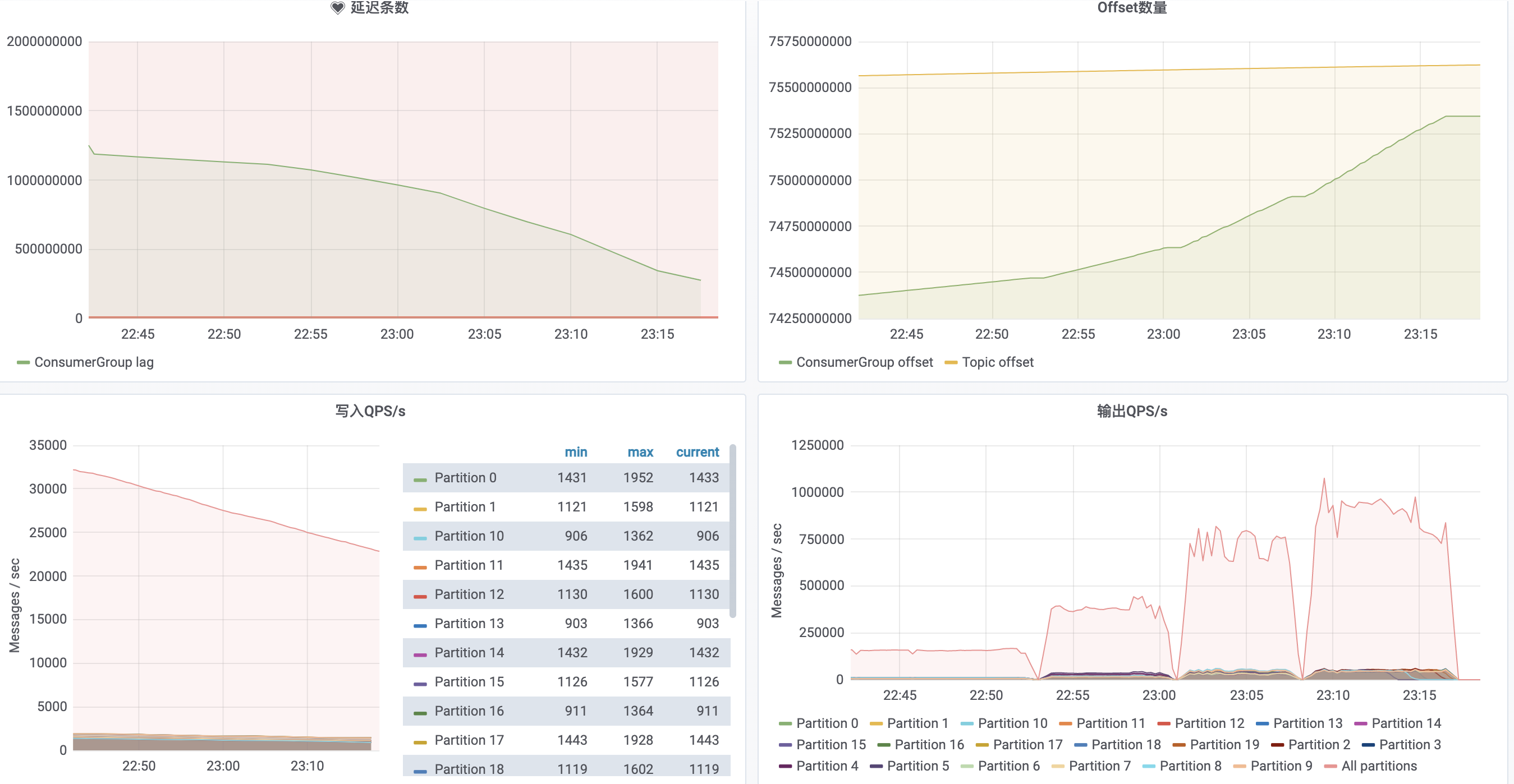
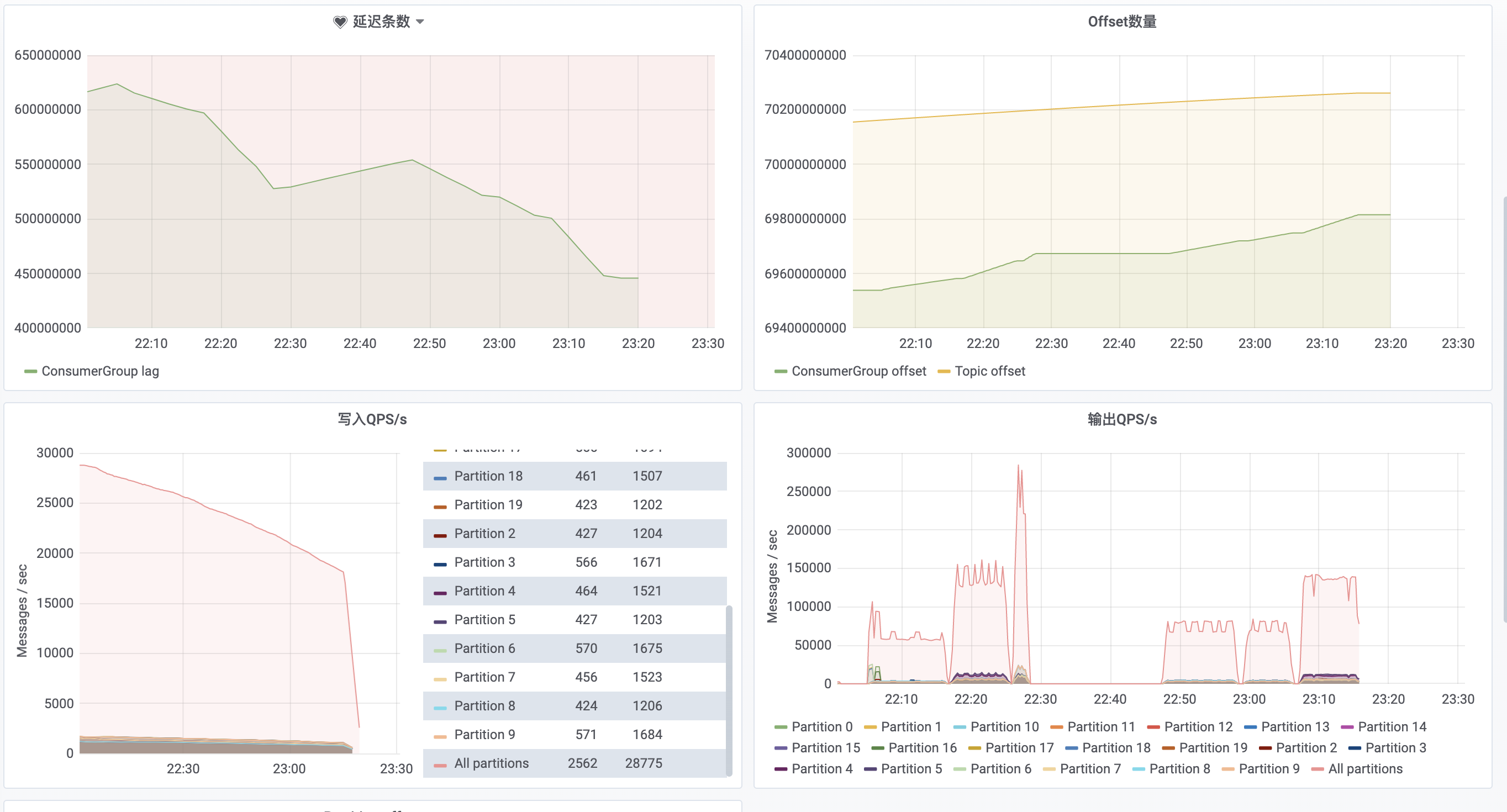
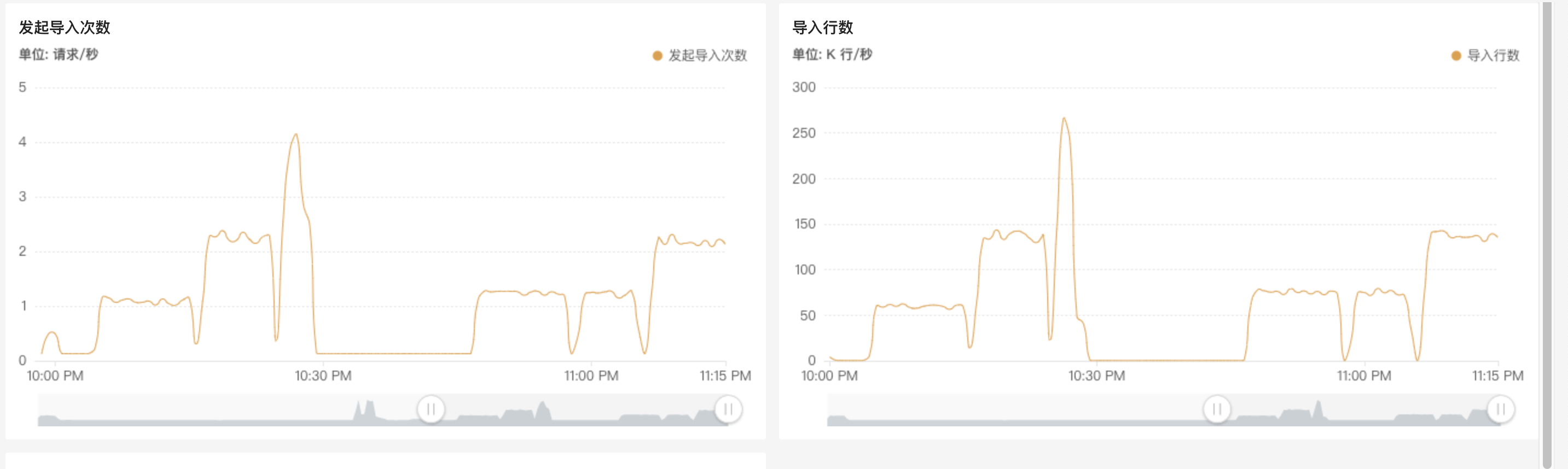
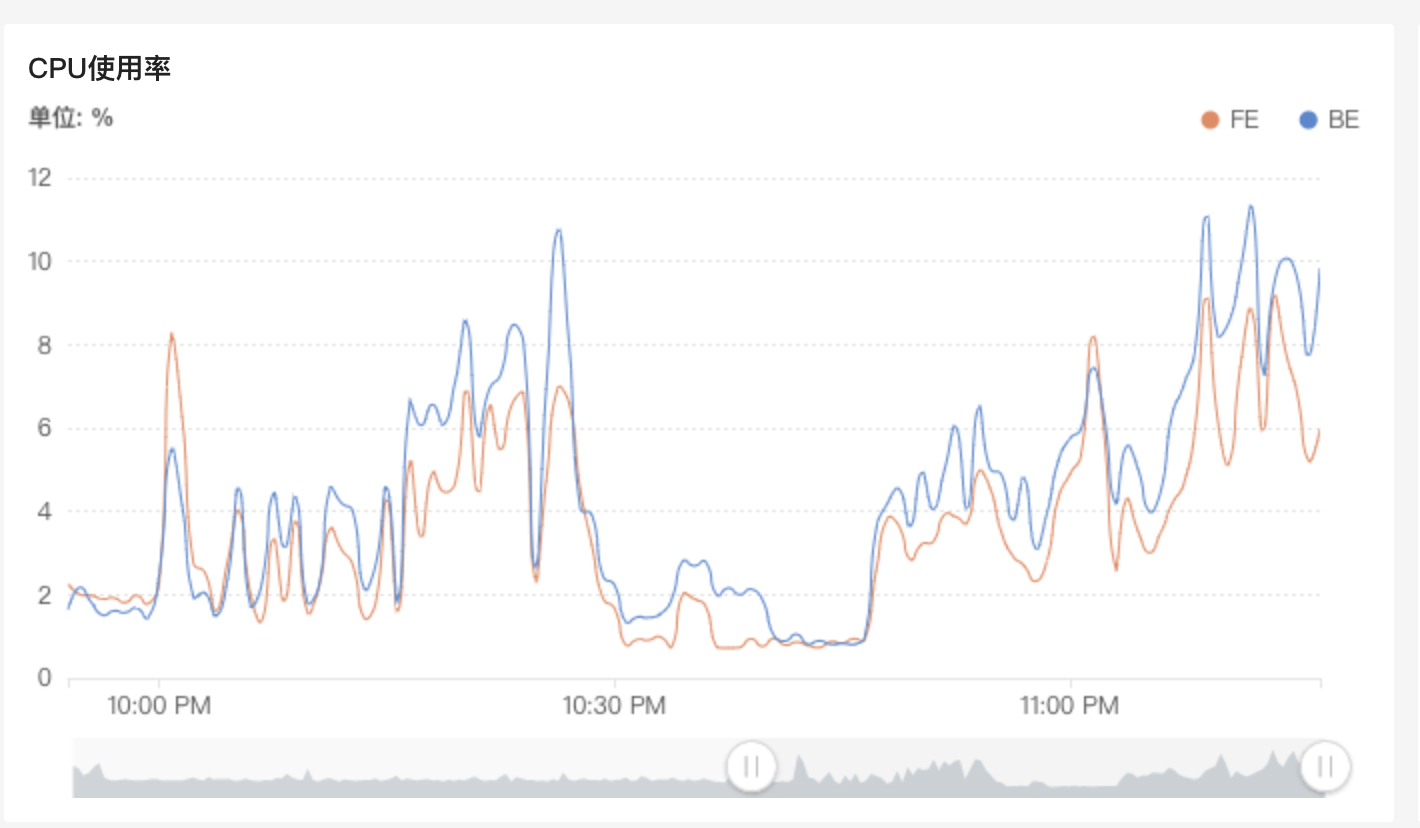
新建 agg 表 imp_flow_agg_big_test,key 列在 40 个左右,混合 bitmap,HLL,sum 指标列,单条数据在 1274 bytes 左右。22:05~22:15 3 个 slot 启动导入,吞吐量在 6w/s。22:15 ~ 22:25 增加到 6 个 slot,吞吐量在 13w/s。
22:25 ~ 22:30 增加到 12 个slot,吞吐量在 26w/s,持续几分钟后触发 close index channel failed,导入频率太快,compaction 没能及时合并导致版本数过多,增量合并数据组达到 300 版本/s。随着吞吐量的增加,cpu 平均使用率线性上升。
22:50 ~ 23:00,调回 3个 slot,增大 TM 内存到 4096M,吞吐量无明显上升,继续增大到 8192M,吞吐量还是无明显上升,单纯增大内存不起作用。11:06 ~ 11:20,调整为 6个 slot,4096M,整个任务的吞吐量在 13w/s,和单纯调整 slot 数差不多。
23:30后以 4 个 slot启动整个任务,平常没有问题,到达流量高峰期后,任务吞吐量达到 8w/s 后,stream load 开始频繁报错进而导致整个任务失败,调整到 3个 slot 后,任务平稳运行,但是写入 qps 比较高,导致任务已经追不上最新 offset。按照官网 FAQ 调整 BE rpc 超时参数,重启 doris 集群后,分别 4~6 个 slot 运行,仍然会有此问题。整个 droris 集群在此期间只有网络 io 繁忙,暂时怀疑和表的分区分片及 compaction 有关系,因为只是测试,简单的设置后 hash(adpos_id) 5个分桶,导致某台节点上的网络压力比较高。
这里没有调节 sink-buffer 系列参数,因为意义不太大,单条数据 1274 bytes,写入 6w qps 的情况下分钟内就可以达到默认的 buffer.max.size 阈值。
 |
 |
 |
uniq 表
新建 uniq 表 imp_flow_uniq_big_test,以某张后续链路 binlog 表为例,从 earliest 开始消费,2w/s 的吞吐。
exactly-once 测试
观察精确一次语义情况下 flink 的资源消耗,此时 doris 摄入完全依赖于每次 checkpoint 的完成。
不适合流量数据,有两点原因:
- json 数据单次最大导入数据 100M。
- 不同时间节点 QPS 的变化造成 checkpoint 存在过大的情况且累计的数据超过 100M导致发送失败。
理论上来说,利用 checkpoint 保证 kafka 精确处理一次 + stream load 的事务保证即可。如果需要使用 checkpoint,可以通过以下方式评估,但是只要涉及到历史数据回溯就会挂。 - 在 chekpoint interval (最小 10ms)时间内积累的数据量有多大,即 checkpoint interval * 写入 qps * 单条 json 数据大小。
flink2doris csv,json 格式导入及 RoutineLoad 对比
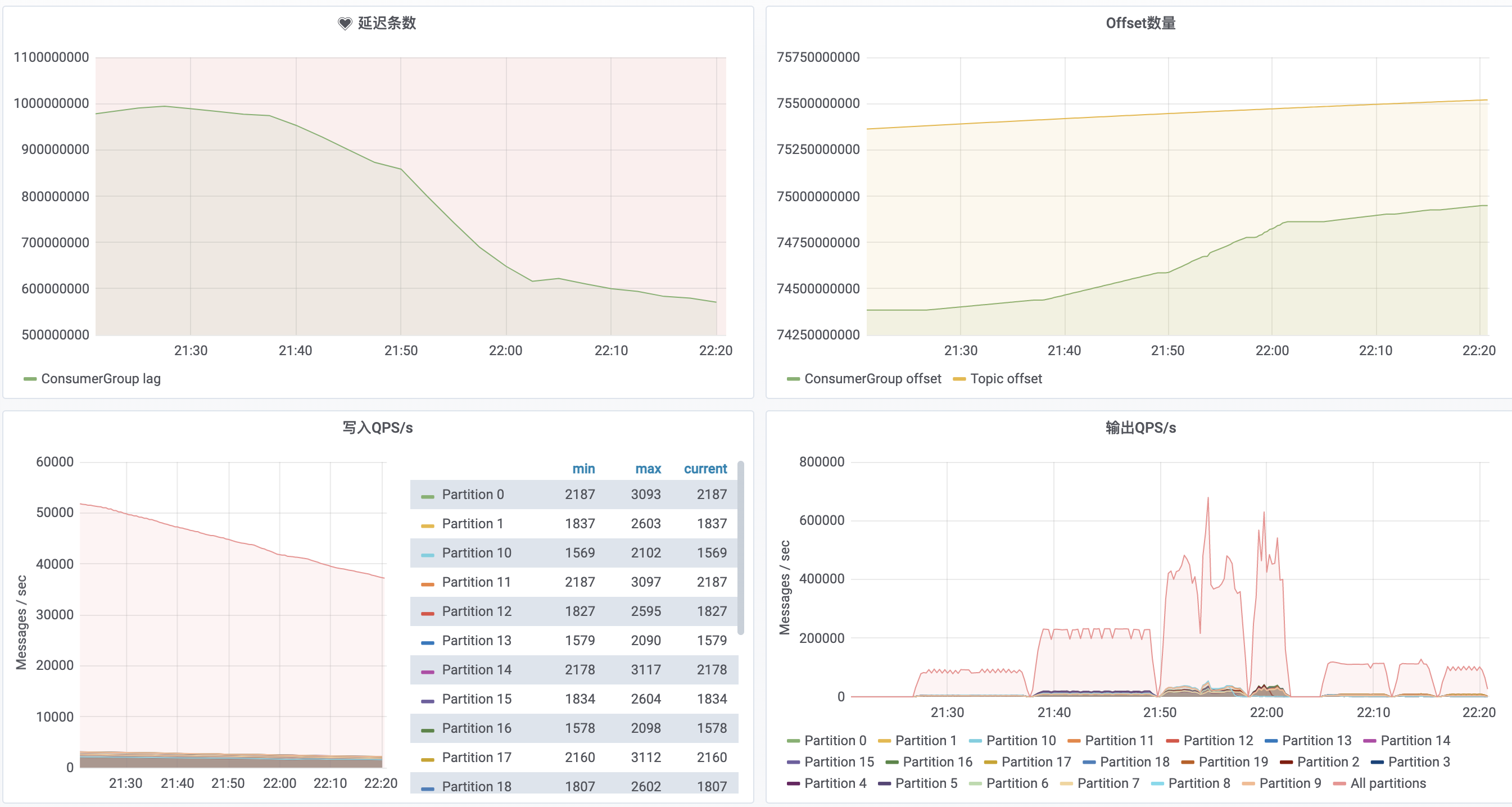
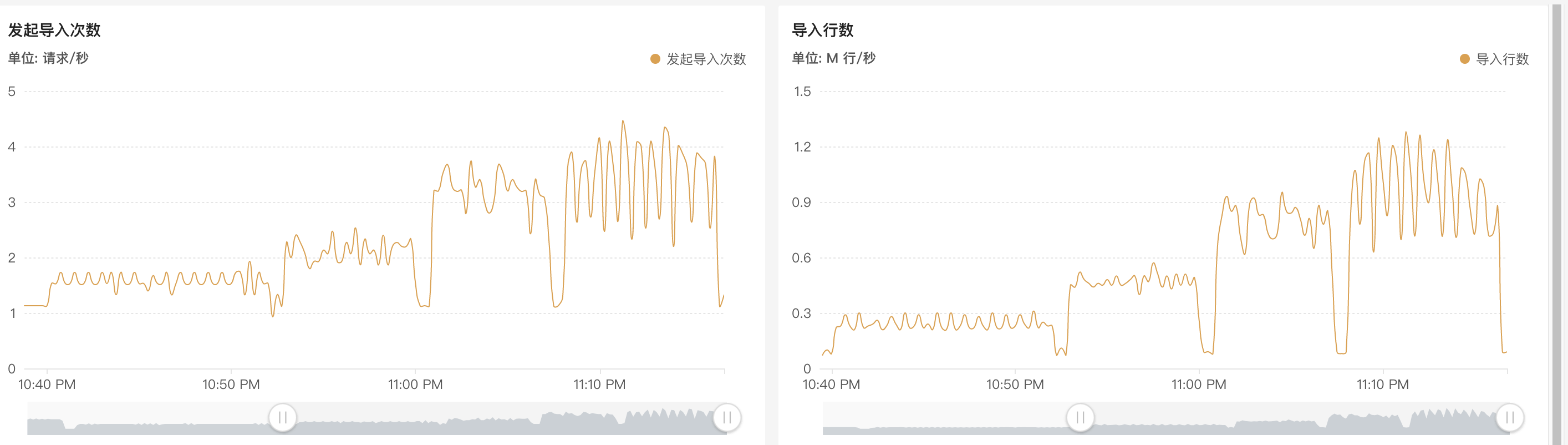
新建 imp_flow_dup_routine_test,和 imp_flow_dup_big_test 表结构一样。以 RoutineLoad 方式导入 imp_flow_dup_routine_test 表,分别以 csv,json 格式导入 imp_flow_dup_bug_test 表。观察整个任务的吞吐。
- csv 与 json 相比,单条数据大小减少了 2/3,吞吐提升了 1/4。
- RoutineLoad 的处理速度平均在 18.5w/s,默认启动 3个 task。task 个数的计算逻辑如下:
Min(partition num, desired_concurrent_number, alive_backend_num, Config.max_routine_load_task_concurrrent_num)。
 |
 |
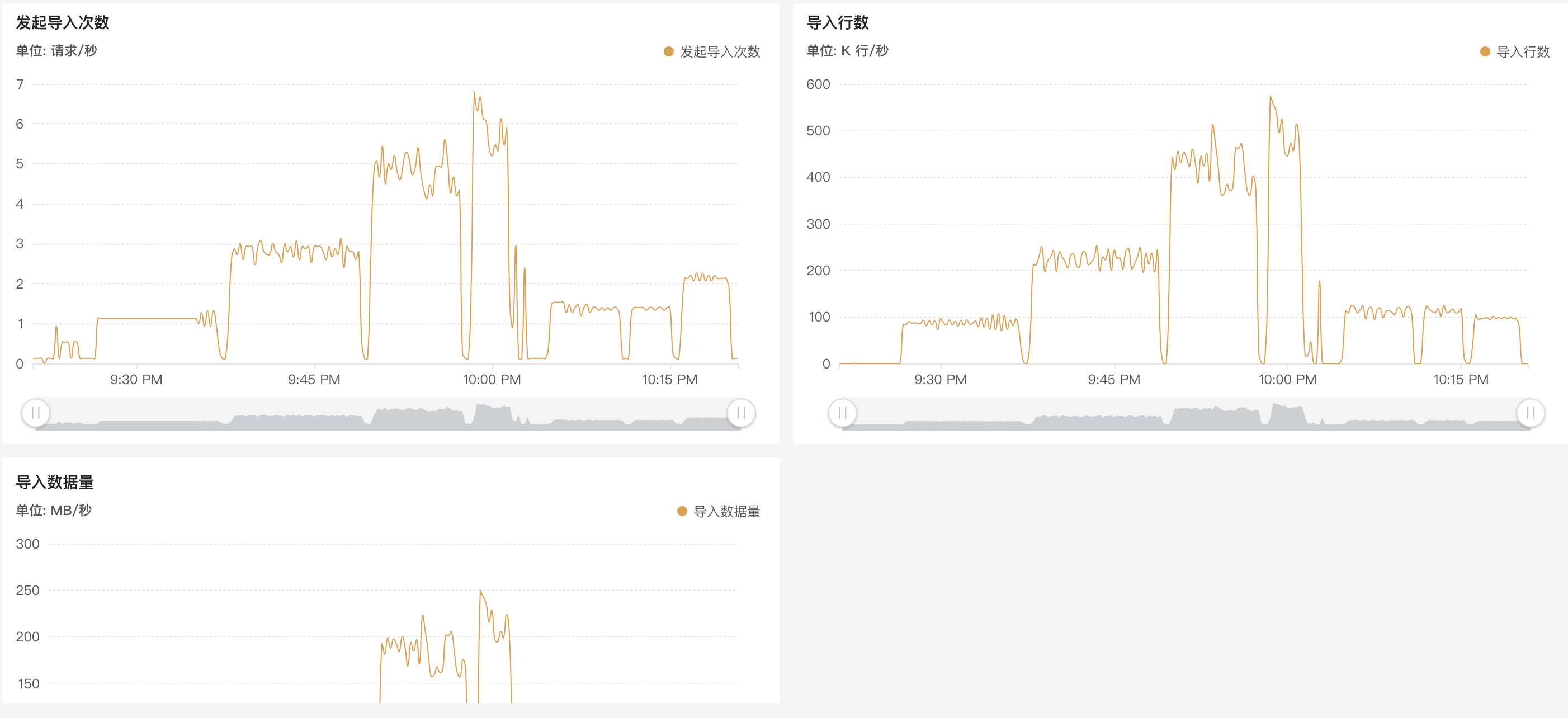
- flink2doris csv 格式只有 10w/s 。
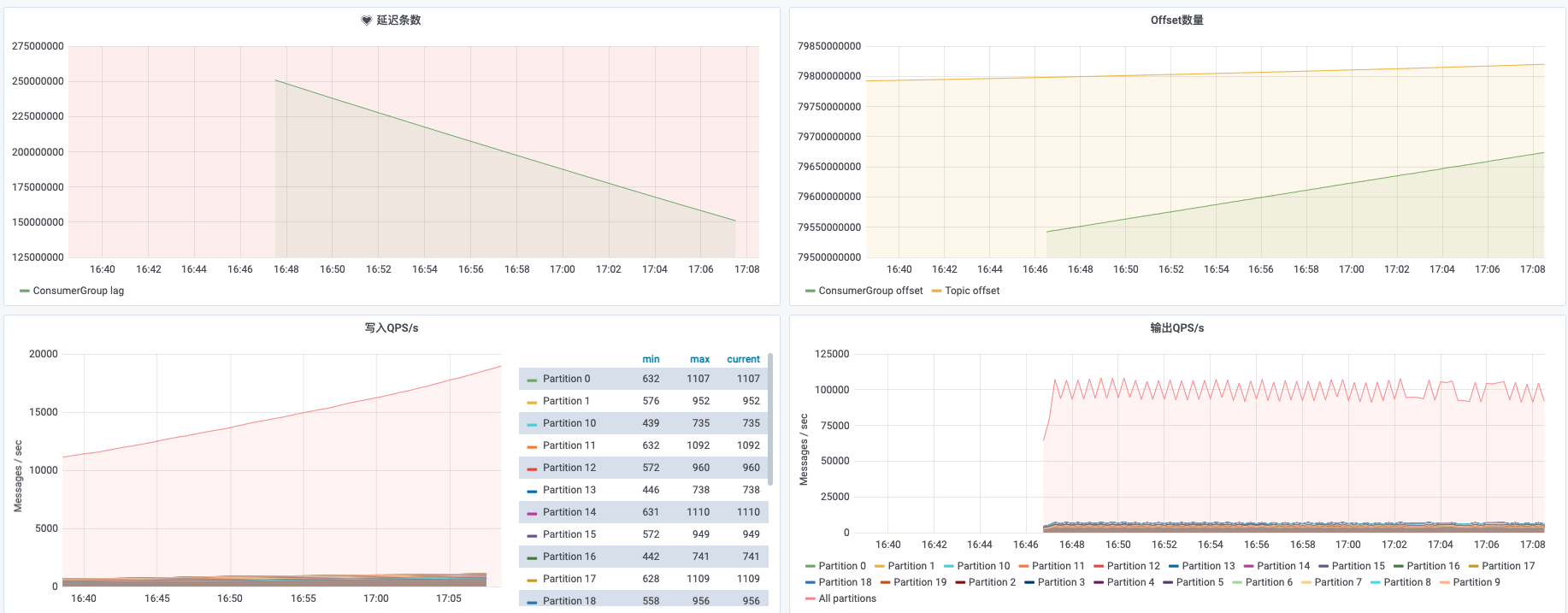 |
- flink2doris json 8w/s,从 sink 端开始反压
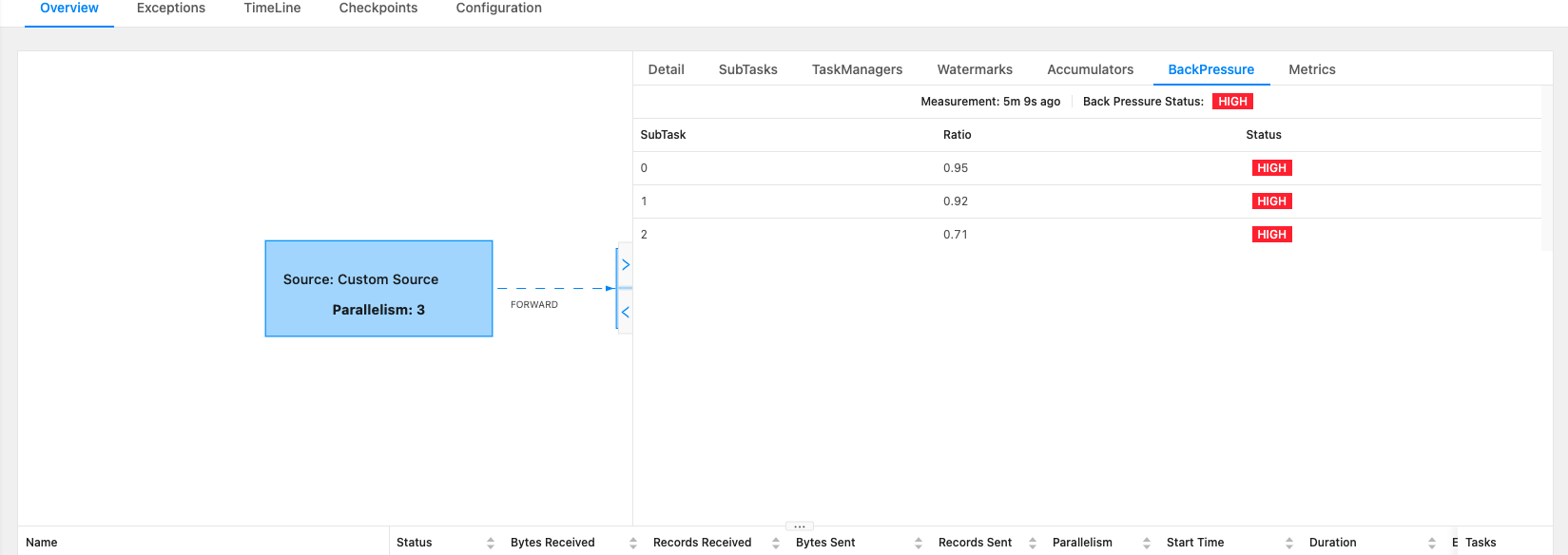 |
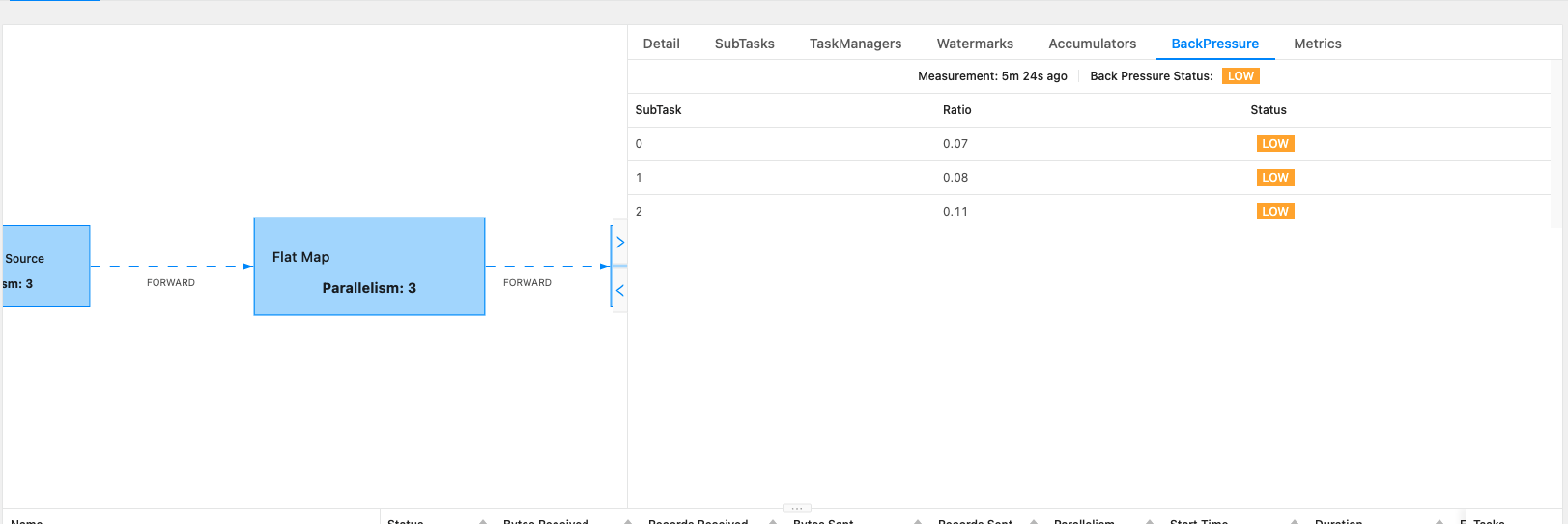 |
集群参数调整测试
修改导入相关的 BE,FE 参数,测试对导入速率以及集群性能的影响。这块相对来说,需要对 doris 的摄入原理有一定的认识,即 doris 的整个数据摄入过程是什么样子的。
- BE 参数
- streaming_load_rpc_max_alive_time_sec。
- tablet_writer_rpc_timeout_sec。
- write_buffer_size。
遇到的一些测试问题
flink-doris-connector 的实现原理?
读取数据缓存在内存中,在 at-least-once 处理语义下,到达某些阈值后(通过 sink.buffer.flush.* 系列参数控制),通过 stream load 发送到 doris。在 exactly-once 语义下,数据缓存在状态中,每次进行 checkponit 时 flush 数据。flink-doris-connector 依赖的引入?
有两种方式,一种是从 dorisdb 私库拉取,可以参考 flink-doris-connector 官方文档。另一种是从中央仓库拉取,参考 flink-connector-starrocks 官方 repo,同时需要额外引入 flink-table-api 的相关依赖。建议第二种方式。数据处理语义问题,at-least-once 和 extratly-once 分别会引入什么样的问题?
- at-least-once → 可能会引起 duplicate 表的数据重复,需要明确下任务失败重启时,已经在内存中但是还没有达到阈值的数据是会丢弃还是立即发送到下游?
- exactly-once → 需要外部系统的 two phase commit 机制。由于 DorisDB 无此机制,需要依赖 flink 的 checkpoint-interval 在每次 checkpoint 时保存已经缓存的数据组及其label,在之后的数据传入时阻塞 flush 所有 state 中已经缓存的数据,以此达到精准一次。但如果DorisDB挂掉了,会导致用户的 flink sink stream 算子长时间阻塞,并引起 flink 的监控报警或强制 kill。
- 字段的映射问题,json stream_load 的顺序问题。有时候某些字段没解析出来?
connector 底层实现是微批 stream load。而 stream load 提供了 columns 参数用于处理字段映射,可以借助这个参数来实现。只要在 columns 中引入数据转换,必须依赖顺序,即 jsonpaths 参数,否则字段映射就会错误。需要在 flink 逻辑中保证顺序。
测试结论
任务的吞吐量大小的衡量可以简单通过 slot个数 * 单个 slot 的 sink 数据大小 / sink单条数据大小 来表达,单条数据越大,slot 的吞吐就越小。在单个 slot 到达瓶颈后,要想增加整个任务的吞吐,只能调整 slot 数量。但是随着 slot 数量的增加,吞吐到达某个阈值后,就会存在稳定性的问题。
不同表数据模型对 sink 的效率影响有限。
flink2doris 性能瓶颈在 sink 端。单条数据 100 bytes 左右,flink2doris 的整体吞吐在 20w/s,单个 slot 在 6~8w/s。单条数据大小增加到 1257 bytes,flink2doris 的整体吞吐在 6w/s,单个 slot 在 2w/s。主要原因是随着数据大小的增加,sink 端很快到达阈值,单次stream load 的处理量降低,sink 端的处理速度降低反压到 source 端,从而导致整体的吞吐量降低。
整体任务的吞吐随着 slot 数的增加线性增长,kafka 测拉回来的数据大小不变的话,与 TM 内存关系不大。
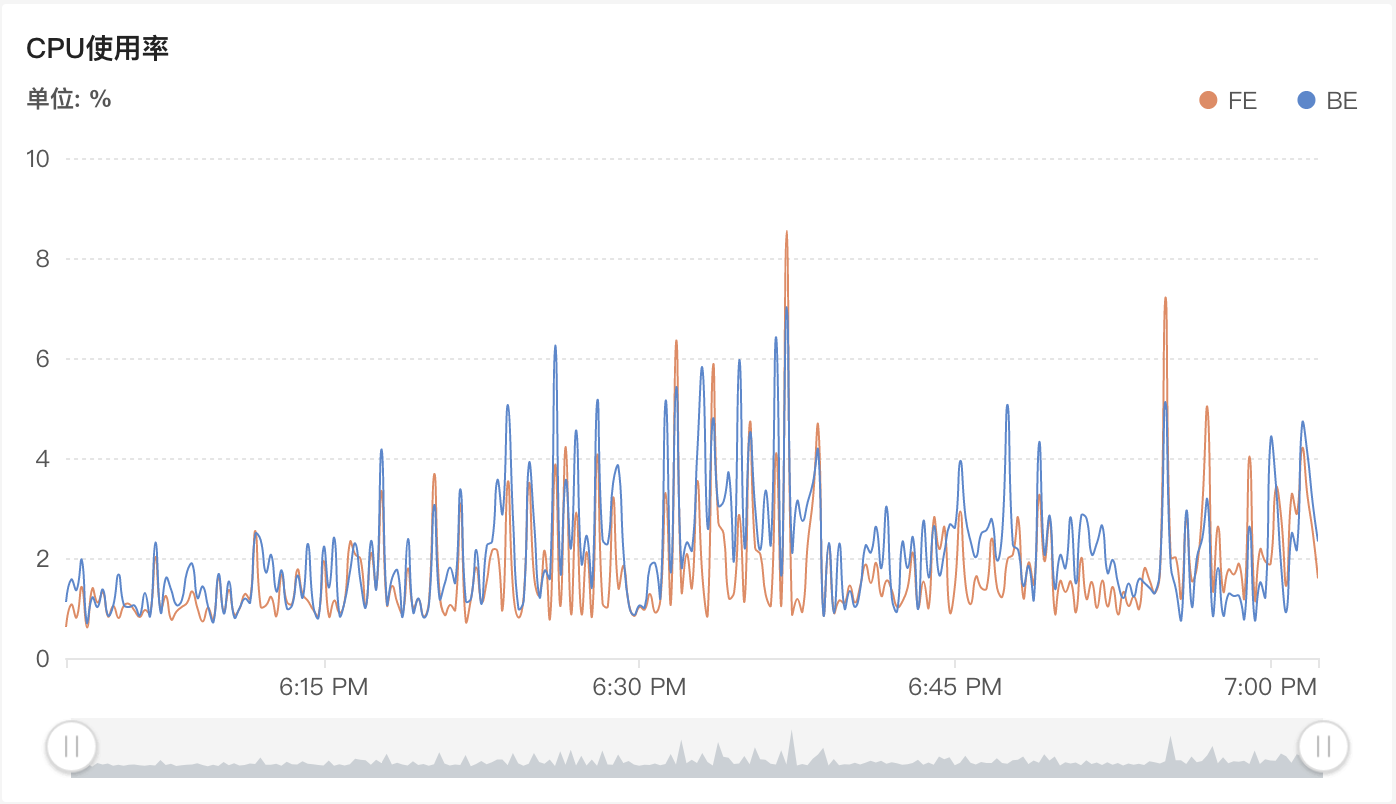
随着 Doris 数据摄入吞吐量的提高,cpu 使用会明显上升。以 3 个 slot 启动三个大测试任务,cpu 平均使用在 5%。增加到 6 个 slot,cpu平均使用 15%。
随着 flink 任务吞吐量以及数据处理大小的提高,flink2doris 开始出现稳定性问题,主要表现为 stream load 失败,看 BE log 的话,怀疑是导入速度比较块,需要合并的版本比较多, fragment_mgr一直占用 tablet 锁, 进而导致 tablet writer 写 RPC 超时。以 IMP 业务数据 doris 摄入为例,吞吐超过 6w/s 后,就会频发
index channel has intoleralbe failure错,进而导致 flink 任务不断失败重启,延迟越来越高。exactly-once 不适用于处理流量数据以及需要频繁回溯的数据。
stram load 在 columns mapping 中引入表达式时,强依赖与 json 字段的顺序,否则会出现映射错误。
RoutineLoad 和 flink-doris-connector 对比
| RoutineLoad | flink-doris-connector | |
|---|---|---|
| 稳定性 | 任务稳定运行。摄入与存储耦合。消耗 doris 集群本身资源,任务多了 cpu 使用会明显上升,可能会影响查询。 | 任务稳定运行,摄入与存储分离。(对于需要频繁更新的大宽表,吞吐量提升到一定后,摄入稳定性会有问题,此时需要调整集群参数。) |
| 可维护性 | 基于 doris 本身的 DML 进行管理,和客户端交互。问题查找涉及 BE,FE log 和 任务本身的错误链接提示,需要对 doris 摄入原理有一定的认识。 | 基于 flink 配置化管理。问题查找可以查看 flink 日志,但是对于 stream load 摄入错误,也要结合 FE,BE log。 |
| 可伸缩性 | 基于以下逻辑控制并发,涉及任务参数以及 BE 参数,需要提前做预估,否则可能需要修改配置和启停集群。Min(partition num, desired_concurrent_number, alive_backend_num, Config.max_routine_load_task_concurrrent_num) | 基于 flink 调整并发,只会涉及到任务启停。 |
| 数据摄入效率 | 高 | 较高(但是某些情况下会比 routinload 吞吐低 40% 左右) |
| 数据回溯支持 | - | - |
| 数据格式支持 | json/csv,对于需要的数据嵌套在不同的 json key 下无法处理。 | 所有 |
| ETL 操作的支持 | columns 参数暴露,但是强依赖与上游数据源中的字段顺序保证,routineload 本身无法做到。 | columns 参数暴露,flink 层逻辑处理。 |