Spark简介
前言
Apache Spark 是一个快速的通用集群计算系统。它提供了Java, Scala, Python ,R 四种编程语言的 API 编程接口和基于 DAG 图执行的优化引擎。它还支持一系列丰富的高级工具:处理结构化数据的 Spark SQL,用于机器学习的 MLlib,控制图、并行图操作和计算的一组算法和工具的集合 GraphX,数据流处理 Spark Streaming。
本栏目主要讲解的是 Spark SQL。Spark SQL 是用来处理结构化数据的 Spark 模块。与底层的 RDD API 不同的是,Spark SQL 提供的接口为 Spark 提供了更多的数据结构和计算信息。在内部,Spark SQL 会根据这些额外的信息来执行额外的优化。我们可以通过 SQL 和 DataSet API 来与 Spark SQL 进行交互。当计算结果时,会使用相同的 SQL 执行引擎,而与你用来实现计算的 API/语言无关。这种统一意味着开发人员可以很容易地在不同的 API 之间来回切换,基于这些 Spark 提供了非常自然的转换表达式。
我个人是在 2019 年 3 月份开始接触 Spark,说实话 Spark 非常容易上手,其接口简洁易懂,尤其是和 Scala 的结合,有时候每个数据处理单元不超过十行代码就可以完成对 T 级别数据的处理,并且速度非常高效。抛却编程语言,只要你会 SQL ,就可以将你的分析任务转换为 Spark 作业来处理。这点对除程序员外的分析人员也是非常友好的。当然其也有限制使用的场景,这些在本栏目下面都会讲到
基本理念
RDD
弹性分布式数据集。分布在集群各个节点上可以并行处理的数据集。其实我们可以按照词的语义来分析想一下 RDD 为什么是弹性的?RDD 是如何分布式的?RDD的数据集到底指的是什么?借用一下官方文档的原话 The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel.
DataSet/DataFrame
Spark 2.X 抽象出来的上层数据结构。本质上也是并行的数据集合。提供了更多的数据操作方法。个人理解为 DataFrame 是一种特殊 DataSet,DataFrame = DataSet[Row]。而DataSet 往往指的是 DataSet[T],T 可以是自定义的数据类型,比如 case class。
Task
具体执行的任务,分为 ShuffleMapTask 和 ResultTask。分别类似于 MapReduce 中的 Map 和 Reduce 任务。
Job
用户提交的 Spark 作业,由一个或者多个 taks 组成
Stage
Job 分成的阶段,一个 Spark 作业常被分为一个或者多个 Stage。 Stage 基于 RDD 的 DAG 依赖关系图进行划分。调度器从 DAG 图末端出发,遇到 ShuffleDependecy 就断开。遇到 NarrowDependecy 就加入到当前 Stage。
Partition
数据分区,即一个 RDD 可以被划分成多少个分区
Shuffle
有些运算需要将各节点上的同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则汇集到一起的过程称为 Shuffle。后面会有单独的文章讲 Shuffle。
NarrowDependency
窄依赖,即子RDD依赖于父RDD中固定的Partition。NarrowDependency 分为 OneToOneDependency 和 RangeDependency两种。
ShuffleDependency
宽依赖,shuffle 依赖,即子 RDD 对父 RDD 中的所有 Partition 都有依赖。
DAG
有向无环图,RDD 之间的依赖关系
tip: Job, Stage,Task,DAG 都可以在 Spark Application UI 上看到。
使用场景
Spark 是 基于内存迭代的计算框架,数据集操作越频繁,操作的数据量越大越适合于 Spark。当然其对内存要求也是比较高的,因此比较重。Spark 操作小数据集并且计算密度比较大时,处理的非常慢,因此不太适合这种场景。我使用 Spark 处理过几 M 大小的碎片文件,竟然需要几十 s 甚至 1min。
RDD 只读并且是写操作粗粒度的,因此不支持异步细粒度更新的应用数据处理。
Spark 不适用于内存 hold 不住的场景,虽然在内存不足时,由于 RDD 是弹性的,其会自动下放到磁盘,但是偶尔也会出现 OOM 的问题,降低性能。
Spark 不适合高实时统计分析,Spark 2.X 的 Structured Streaming 也在快速发展,Continuous Processing还处在试验阶段。但是其受限于 RDD 以及其他原因,还是无法媲美 Flink 在高实时数据流方面的处理。
架构
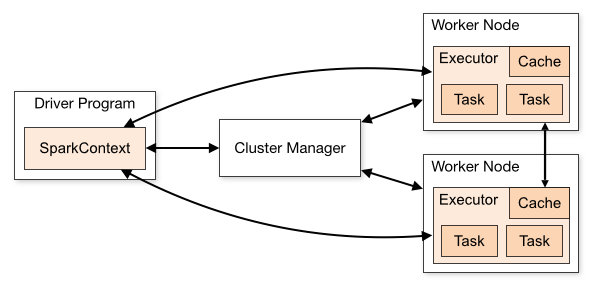
Cluster Manager:在 standalone 模式中即为 Master 主节点,控制整个集群,监控 worker。在 YARN 模式中为资源管理器。
Worker节点:从节点,负责控制计算节点,启动 Executor 或者 Driver。
Driver: 运行 Application 的 main() 函数。
Executor:执行器,某个 Application 运行在 worker node 上的一个进程。运行 task 和 管理运行过程中的数据存储
Spark 应用程序作为独立的进程集运行在集群上,通过 Driver Program 中的 SparkContext 对象来进行调度。一旦连接上 Cluster Manager(YARN,Spark 自带的 Standalone Cluster),Spark 就会在对应的 Worker 上启动 executor 进程用于计算和存储应用程序运行所需要的数据。接着你的应用程序代码会被发送到各个 executor 。SparkContext 会调度生成 task 在 executor 进程中执行。
Spark 编程模型
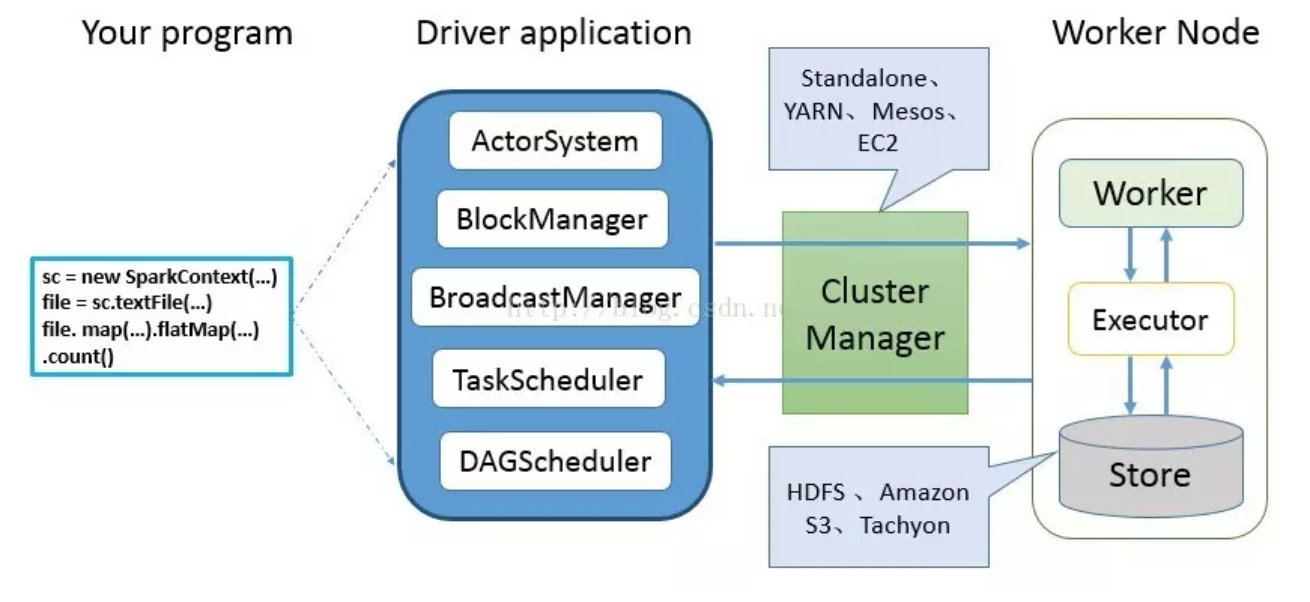
用户使用 SparkContext 提供的 API(常用的有 textFile、sequenceFile、runJob、stop、等)编写 Driver application 程序。此外 SQLContext、HiveContext 及 StreamingContext 对 SparkContext进行封装,并提供了 SQL、Hive 及流式计算相关的 API。Spark 2.X 提供了更为方便的 SparkSession(DataFrameReader、DataFrameWriter)。
使用 SparkContext 提交的用户应用程序,首先会使用 BlockManager 和 BroadcastManager 将任务的 Hadoop 配置进行广播。然后由 DAGScheduler 将任务转换为 RDD 并组织成 DAG,DAG 还将被划分为不同的 Stage。最后由T askScheduler 借助 ActorSystem 将任务提交给集群管理器(Cluster Manager)。
集群管理器(ClusterManager)给任务分配资源,即将具体任务分配到 Worker 上,Worker 创建 Executor 来处理 task 的运行。Standalone、YARN、Mesos、EC2等都可以作为 Spark 的集群管理器。
Spark 计算模型
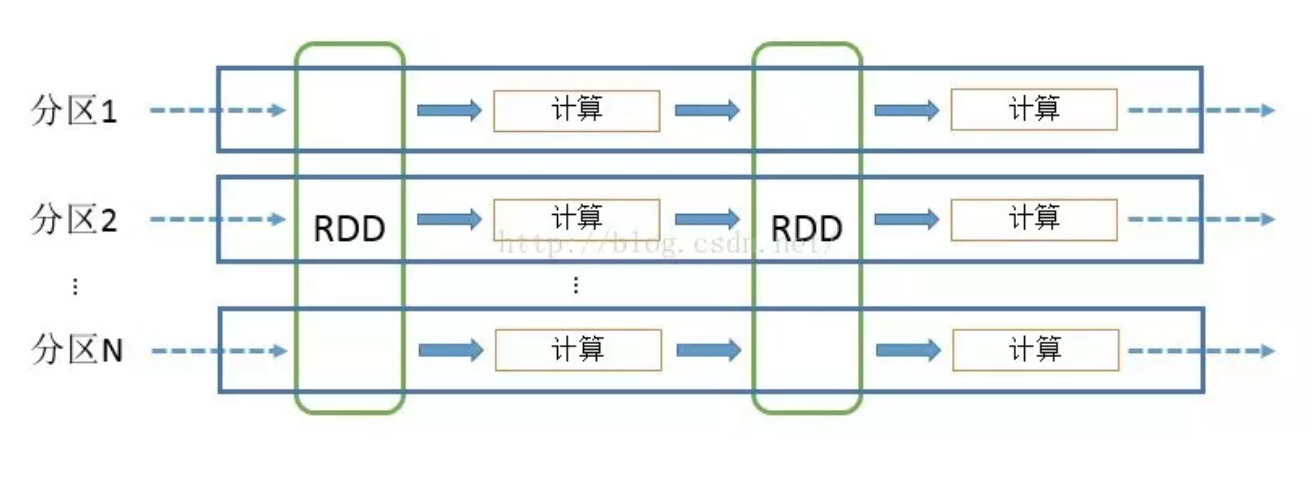
Spark 是基于内存迭代计算的框架,底层数据抽象是 RDD,通过算子来对 RDD 进行转换计算,得到目标结果。
Spark 运行流程及特点
运行流程
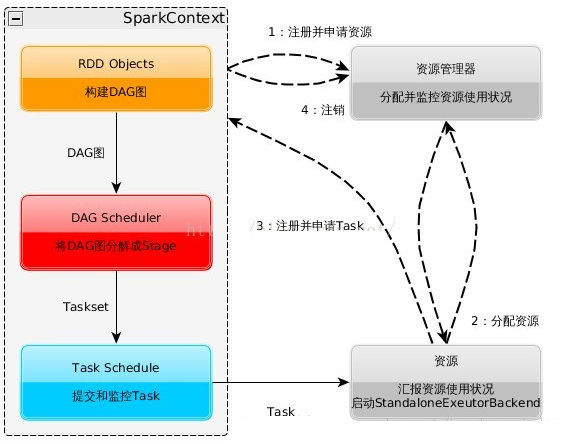
启动 SparkContext
SparkContext 像资源管理器申请 worker Executor资源并启动 StandaloneExecutorbackend
Executor 向 SparkContext 申请 Task
SparkContext 将应用程序分发给 Executor
SparkContext 构建成 DAG 图,将 DAG 图分解成 Stage、将 Taskset 发送给 Task Scheduler,最后由 Task Scheduler 将 Task 发送给 Executor 运行
task 执行完毕后释放资源
特点
每个应用程序都运行在自己的 executor 进程里面,在 executor 里面又以多线程来运行各种 task。这样做的好处很明显,每个 driver 都只需调度自己的 task。来自不同应用程序产生的 task 都在在不同的 JVM 中运行。当然,这也意味着,不同 SparkContext 实例之间不能共享数据,只能先存储在外部存储系统,然后在做交互。
Spark 与应用哪种集群管理器无关,只要可以获取 executor 进程并且 driver 和 executor 端可以保持通信,即使运行在还支持其他应用程序的的资源管理器(YARN 等)也是非常容易的
在应用程序的一个生命周期内, driver 和 executor 端必须可以通信,否则无法分发 task及运行信息交换。这就要求 driver 端和 各个 worker 节点是网络连通的,并且 driver 端要尽量靠近 worker 端,因为 Spark Application 运行过程中 SparkContext 和 Executor 之间有大量的信息交换。
RDD 运行流程
RDD 在 Spark 中运行的大致流程
1.创建 RDD 对象
2.DAGScheduler 模块介入运算,计算 RDD 之间的依赖关系,生成 DAG
3.根据 DAG 划分 Stage,上面的基本概念里也简单提到了 stage 的划分。

基于上面的例子来划分 stage,在遇到 shuffle 依赖时,DAG 会断开依赖关系,前面的操作划分为一个 Stage,后面的继续按照这样来划分。例子中总共涉及到 RDD 的 4 次转换,action 算子collect 不会触发 RDD 的转换生成。所以在这里 groupByKey 操作涉及到 shuffle。由此 shuffle 之前的操作会作为一个 stage 来处理。最终划分的 stage 结果如下
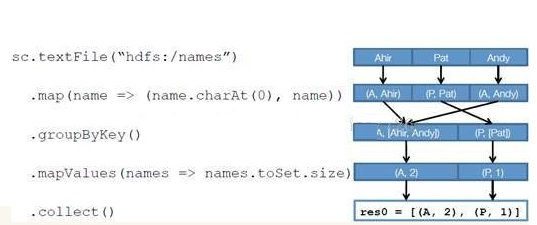
Task Scheduler 会接受各个 stage 阶段划分的 task 并分发到 executor 中运行。一个 stage 阶段 task 的运行必须等待上一个 stage 阶段的 task 全部运行完。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
Spark 3.X 展望

Spark 将支持 Stage 级别的资源控制和调度。目前 Spark 支持对 executor 资源的控制,但是往往一个 spark 作业分为几个 Stage 阶段,每个阶段用到的资源也是不一样的。支持 Stage 细粒度界别的资源控制有助于我们更好的控制集群资源。详情见 SPARK-27495
Spark Continuous Processing 模块
Spark Delta Lake
Spark SQL 对事物的处理,支持 CURD。