druid 离线摄入任务优化
前言
最近 Yarn 队列资源收缩后,部分流量数据的 druid 离线摄入任务执行时间过长,经常由于申请不到 container 导致并发过低或者 reduce task 频繁失败重试,耗时 6~8h 才能完成。由于本身已经是 T+1 数据,离线摄入执行过长对下游使用方造成了很不好的使用体验。本文主要记录如何定位问题及如何解决。
前提问题
一般碰到性能优化问题,都要对任务的执行情况有一个比较深入的了解,什么阶段发生了什么,哪个阶段耗时最长,任务的执行环境等等信息。这里首先会抛出一些问题,看看我们该如何获取我们想要的信息,包括各阶段的日志查看,任务运行的环境参数。
MR 作业 map 阶段 spill 的次数该怎么查看?
主要分为三段日志,开始读文件,此处可以看到集群 mapre 的环形缓冲区大小是 892M,该map 处理的是 119 M 的文件。根据使用的 InputFormat 不同,日志会有差异,这里不一定会打印出文件路径。
发生 spill
spill 完成,这里只溢写了一次。
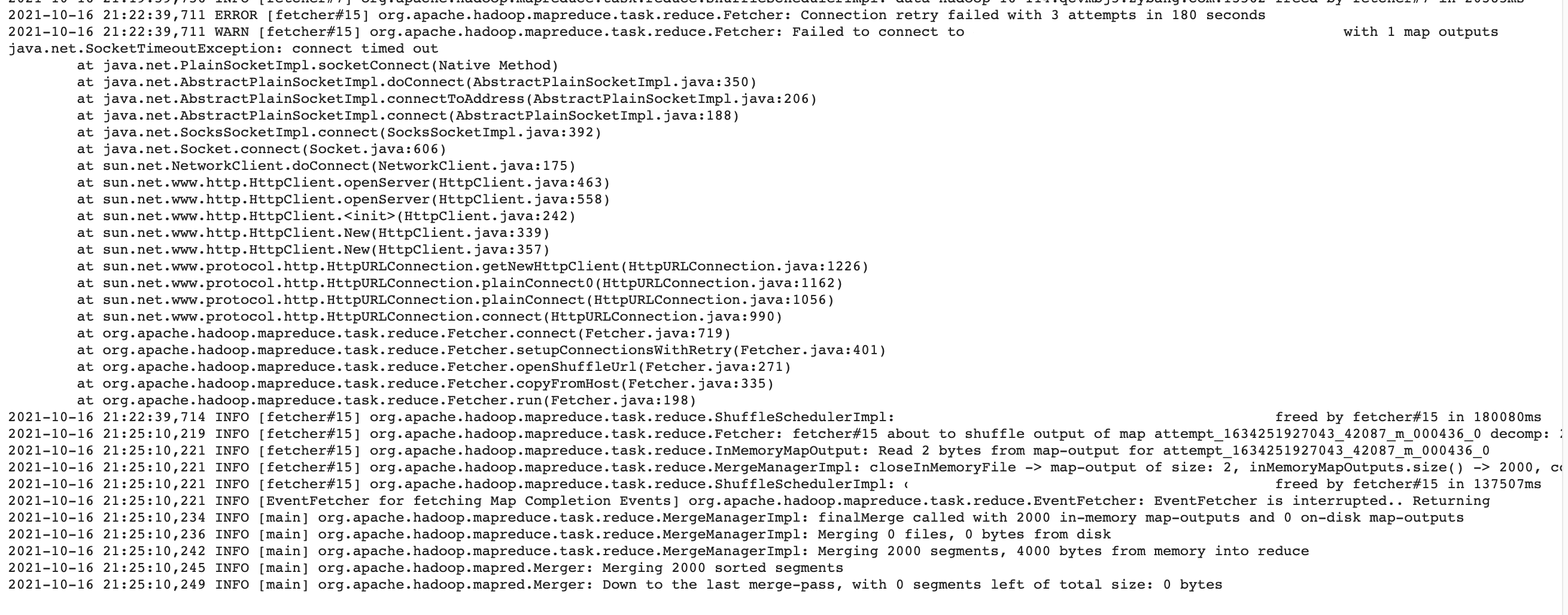
MR 作业 reduce 阶段 fetcher 失败重试的日志怎么查看?
reduce shuffle log 中查看,fetcher#15 失败了三次,原因是连接存放目标 map 文件的机器超时。也可以查看 job counters 中的 shuffle error group。
GC 日志怎么查看,该怎样定义 GC 频繁?
JVM 参数开启。如果发生多次老年代 GC 或者 metaspace GC,则需要注意内存是否给小了。关于 GC 日志如何查看可以参考 此处1
-XX:+PrintGCDetails -XX:+PrintGCDateStamp

Hadoop 默认参数在哪里看?
这点是极其需要注意的,不要按照官网默认参数来调整,要按照自己集群的默认参数来调整,一开始就改错了,环形缓冲区大小 892M,官网默认大小 100 m,一开始调整成了 500M,本来是想增大结果调小了。
查看以往摄入任务的 MR 中的 Job configuration,搜索自己要调整的参数查看即可。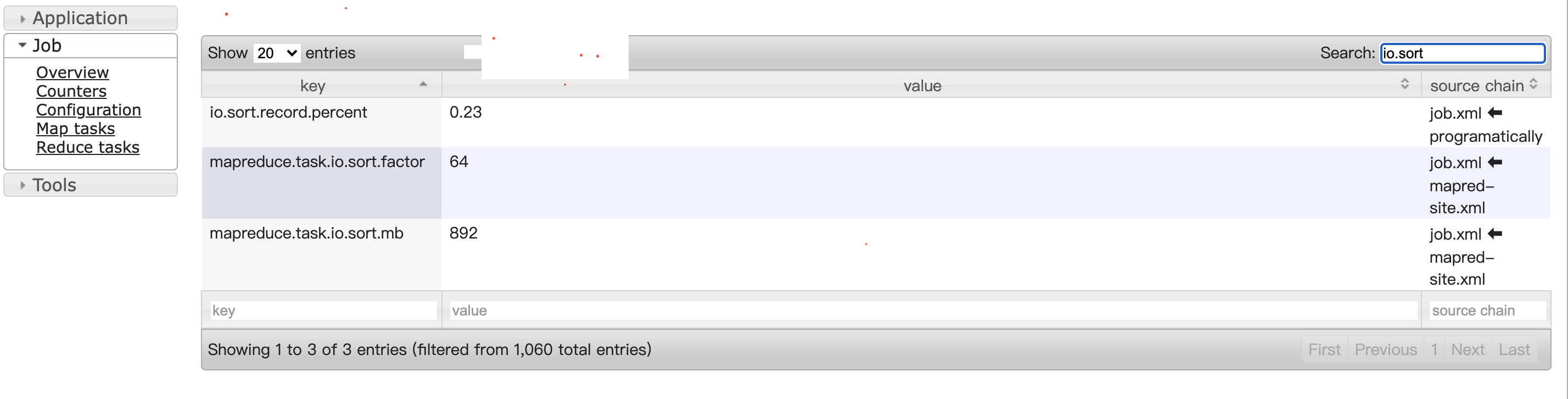
reduce 阶段 sortmerge 日志的含义?
merge 拉取到的上游文件交给 reduce 逻辑去处理。
MR 作业 counters 的查看,对于任务分析有什么意义?
相关 counters 的含义参考 此处,相当于 MR 执行统计,对理解 MR 执行会有很大帮助,一般出现 shuffle error 的话,会极大影响整个作业的执行效率。为什么被 kill 重试的 reducer 往往是最后才执行,并且一直占用着资源,处于 NEW 状态?
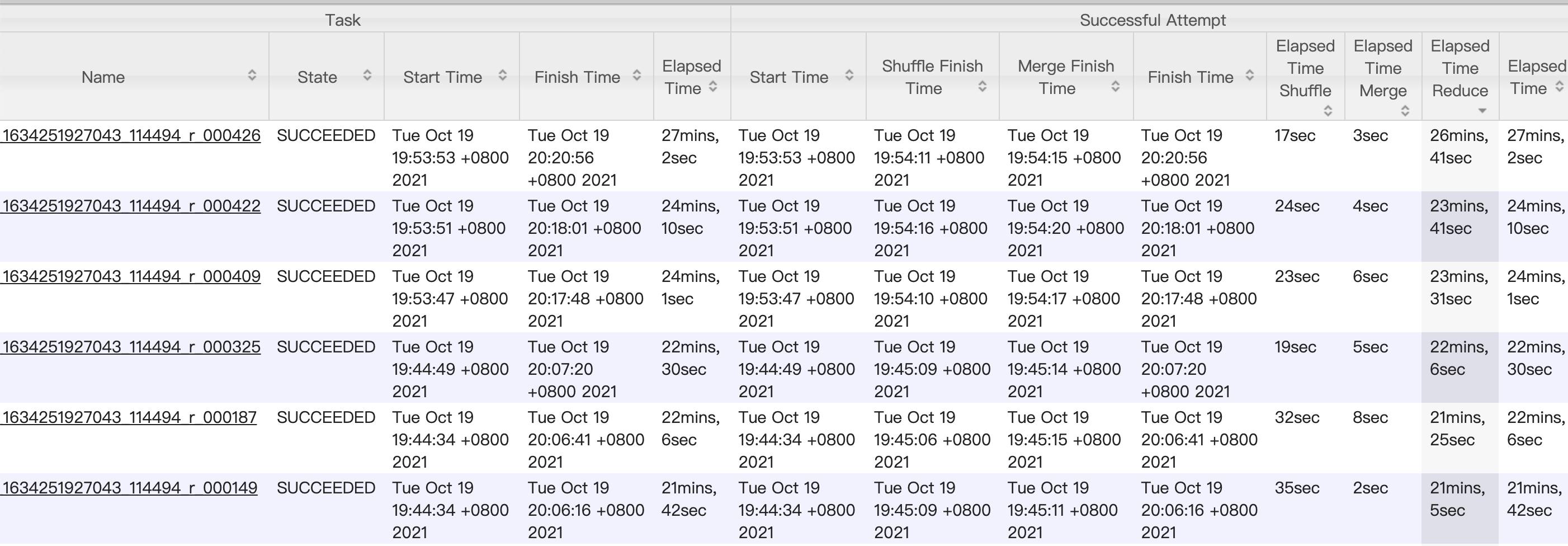
为什么 reduce 逻辑处理相同数据量(大小)的数据的时间差异比较大,快的 8min,慢的到 50min?
主要有两点原因- 存在 shuffle error,网络 io 错误造成的 fetcher 超时非常容易引起 map 和 reduce 的循环重试。
- 受执行机本身影响,比如下面这几个 reduce task,当时运行的机器上内存和 cpu 消耗都非常大。
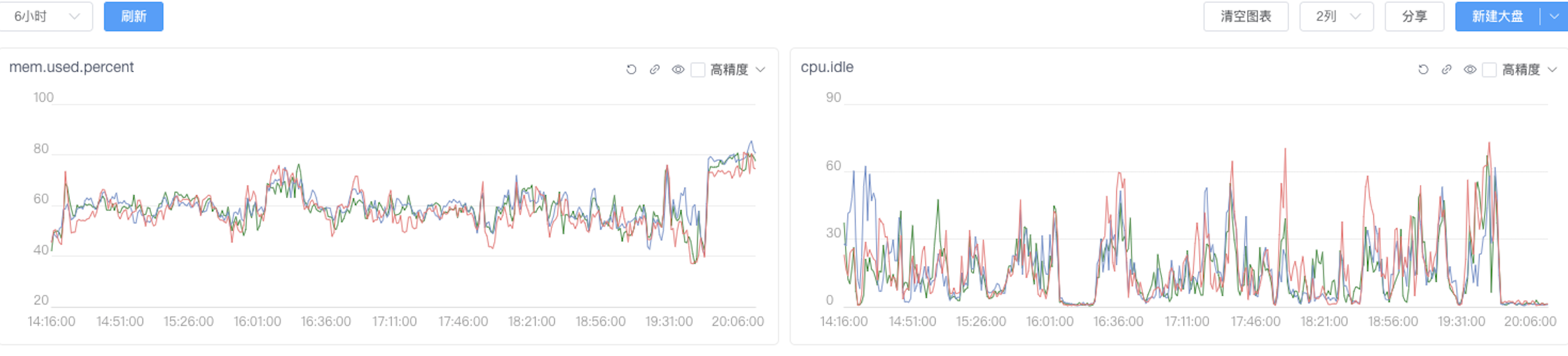
任务执行现象
明确了上述前提问题,我们就需要去日志中查看分析,总结出来任务的执行现象,即任务由于哪些问题才导致的慢,最后根据总的问题来去优化,而不是想当然。
以其中某天数据为例,观察任务执行情况
处理数据量
读取 cos 上的文件,总共 4000 个文件,总计 355.5 G,平均大小 91 M,block 大小 为 16M,1 副本。使用的是单独的文件存储。
1 | $ hadoop fs -stat "%o %r" cosn://xxx |
MR 参数
1 | "mapreduce.job.queuename": "xxx", # 执行队列 |
任务执行情况
- MR job 启动了 24000个 map,960 个 rercuer。
- map 阶段任务并发 500 左右,基本上 1min 内完成,平均耗时 30s左右,估算时间在 24000/500 *0.5=24min,最终执行了 31min。
- reduce 阶段任务一开始并发 55~70 左右(受执行机空闲 core 数影响),分为三个阶段 copy → sortmerge → recuce,copy 阶段读取 map 为下游生成的 24000 个 map 文件,fetcher 速率受网络 io 和并发参数影响,平均拉取完成时间在 6 min 左右,平均拉取文件大小在 10000 ~ 40000 bytes 之间,即 0.04 M,并发起来后,会偶发拉取超时。查看其中一个 task,merge 结果如下,reduce 总体耗时在 16 min 左右,受拉回的上游文件大小影响。
- 2min内完成 reduce占比为 1/6,200 个,上游 map 生成的文件比较小。执行完之后,发现执行时间为 2min,10min,20min,40min, 几个小时 的执行成功的reducer 都占一定比例。在 reduce 阶段被 kill 掉的 task 有 459 个,map task 由于下游 reducer fetche 超时等原因重试 3720 个。
任务最重执行结果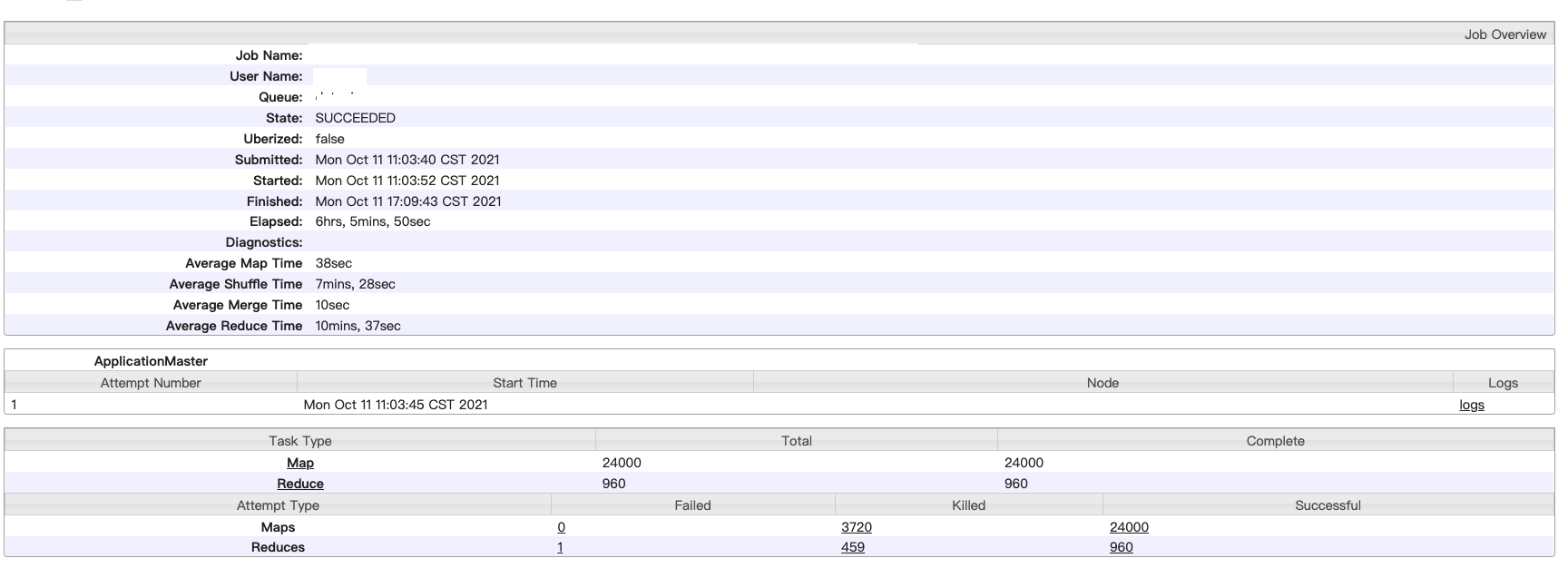
现象总结
- cos 文件 blocksize 16M,启动 map 数过多,map 平均耗时 30s,进而分配资源开销占比比较大。在队列资源比较紧张的时候,并发数上不去,进而导致相同时间段内处理的数据量差异比较大。
- reduce 阶段 task 执行完成时间差异比较大,发现 2min,10min,20min,40min, 1h 内执行成功的reducer 都占一定比例,reducer 处理的数据不均匀。
- reduce 由于 fetcher 拉取超时和 reduce 阶段内存不足等原因失败重试,fetcher 超时会让 reduce 认为上游 map 失败,进而导致上游 map 重试,重试的 map task 优先级比较高,没有资源的情况下会抢占 reduce 资源,进而导致部分 reduce 失败。fetcher 阶段 10个线程并发拉取 35M (24000 个临时文件)数据花费了 4min 左右,fetcher 耗时比较长。
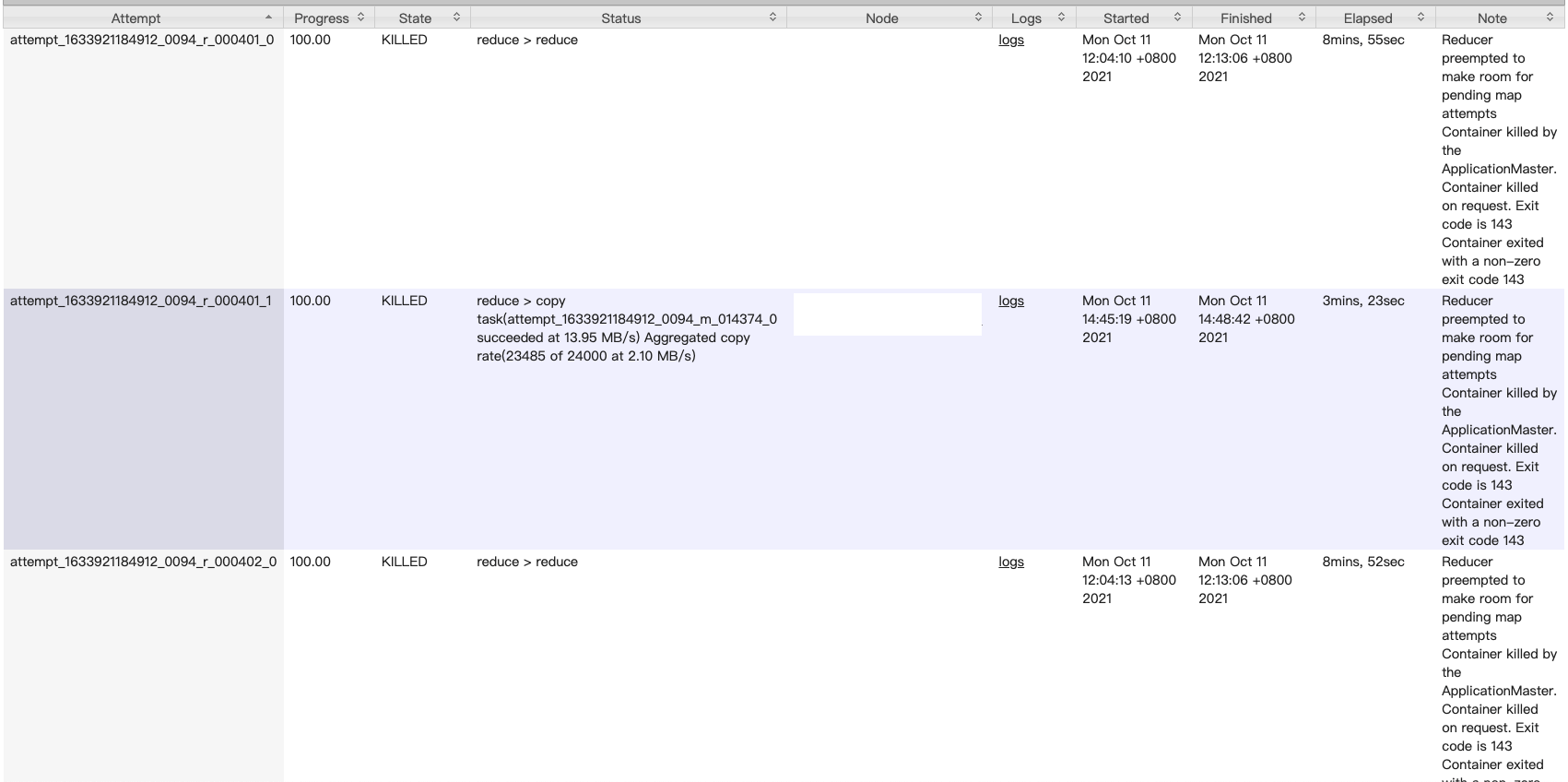
- 当天存在异常任务,部分执行机磁盘打满了,导致节点不可用,进而运行在上面的 reduce task 失败。
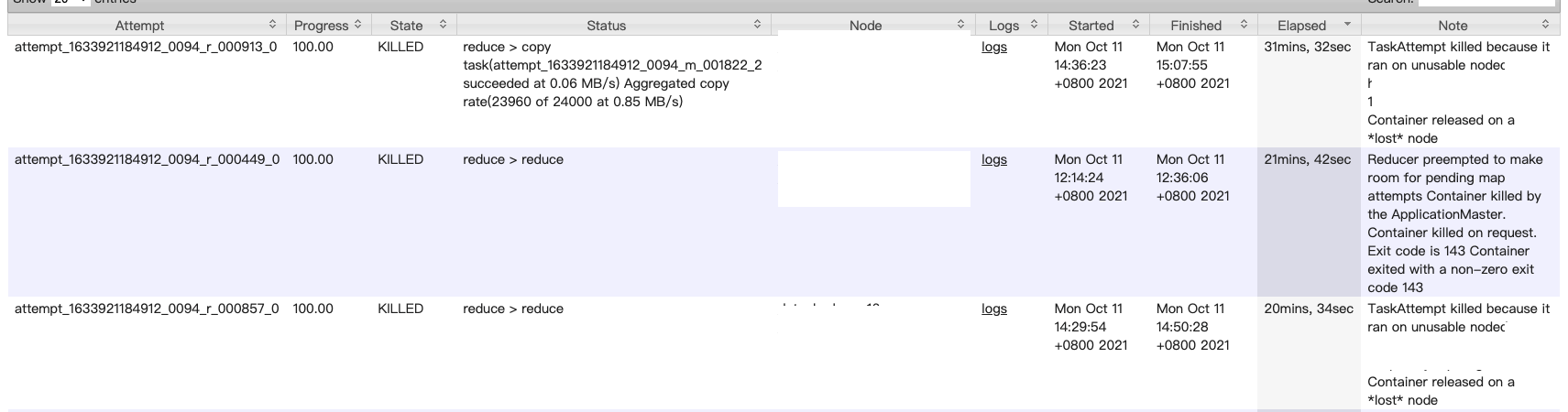
- reduce sortMerge 后的数据部分存储在内存和磁盘中,在走 reduce 逻辑的时候会有磁盘 io。
- 由于 fetcher 超时被 kill 掉的 reducer task 一直占用着 core,但是不执行,任务状态一直为 NEW。
- 观察同期执行的 druid 合并任务,只有 140 个 map,查看 jobCounters,shuffle write 的数据量一致,都是 200G 左右,但是 map 读取的字节数差异很大,一个是 237G,一个是 35G,读取压缩文件比读取单纯的文件文件效率要高不少,可以查看 map 整体耗时。
有时候我们明确了问题,但是不知道内部为啥这样执行,会涉及到哪些参数,数据结构,这时候就需要去了解所使用框架的实现,不管是查看源码还是网上搜索。
MR job 的执行过程
可以参考此图,比较详细。
总结一下,大致就是 split→ map → 环形缓冲区 → spill 文件 → sortMerge → reduce fetch → sortMerge → spill → reduce,其中是否发生 spill 主要受 shuffle write,sortMerge 阶段 buffer 的大小。
对于 druid 离线摄入任务来说,在集群 cpu,内存等资源都充足的情况下,需要关注 map 个数以及 shuffle 阶段,这里的 reduce 的逻辑可以暂时忽略(受 druid 本身影响)。
Druid 离线摄入任务的执行过程
本质上是 json2MR 的过程。根据设置的参数判断是否启动不同阶段的 MR。主要有三类 MR job。
determine_partitions_hashed job,设置了 targetPartitionSize 后,首先会启动该 MR job,用于确认分区,计算分区的逻辑在 DetermineHashedPartitionsJob 类,逻辑可以参考 https://blog.51cto.com/u_10120275/3530686 。就是利用 HLL 估算给定的查询粒度范围内的数据基数,在除以 targetPartitionSize 计算该时间范围内逻辑分片数。比如1小时内数据量 1000w,targetPartitionSize=200w,最终的分片数就是 5 。通过查看摄入任务的日志,可以看到每个时间段内确认的分区结果。需要注意 targetPartitionSize 并不是绝对的,一般还会由 maxPartitionSize 来限制,默认是 50%的targetPartitionSize。最终每个 segment 的行数范围是 targetPartitionSize ~ maxPartitionSize。
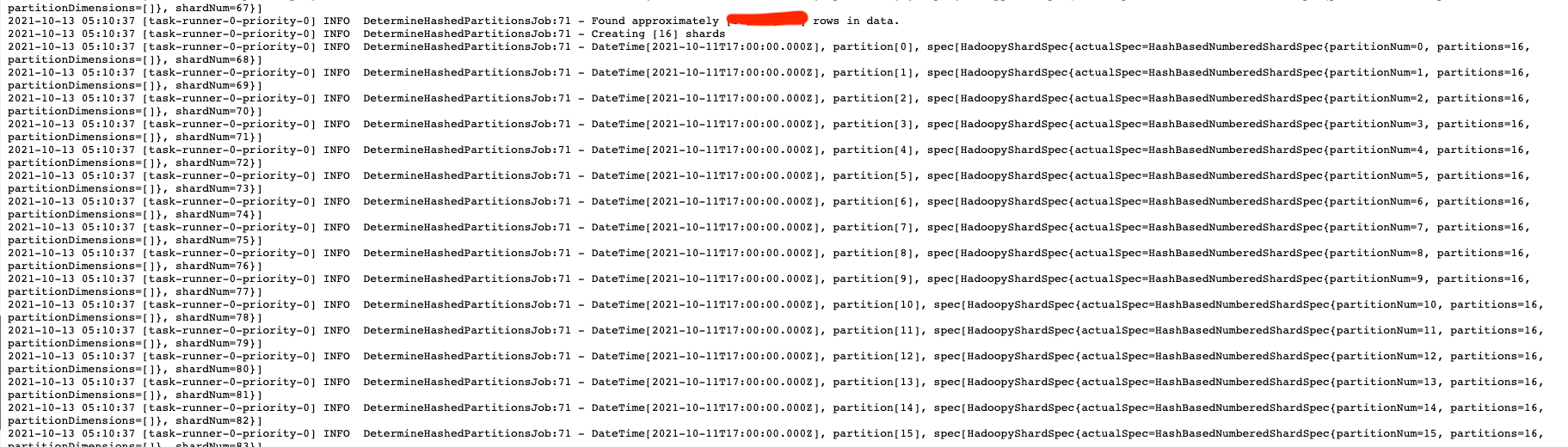
引入 targetPartitionSize 需要考虑几个问题。
- 需要估算 segemt 的大小和数量,避免又引起查询性能问题。
- 启动的 reducer 个数会随着数据量浮动,有可能更少,也有可能更多。少了会导致每个 reducer 处理的数据量比较大,加大内存消耗,会拉长整个 MR 的执行时间。
- 整个摄入任务又多了一个 MR,如果均匀分区的执行效率没有太大提升,有点得不偿失。
build-dict job,如果存在 uv 类指标,则会启动该 MR,reducer 的个数在代码中被写死,等于精确 uv 类指标的个数。
index-generator,主要是 segment 的构建逻辑,可以参考 https://cloud.tencent.com/developer/article/1618957。
除了上述 MR 过程外,摄入任务首先会注册 lifecycle,逐个执行生命周期内的所有逻辑,包括 lookup 等,这部分执行时间一般为几min。比如加载 lookup 到执行机 cache,执行 69 个 lookup 的时间在 1min 内,后续 MR 会从 cache 中读取。
参数调整
在做参数调整前,需要了解默认参数是啥样子的,这里的默认参数不是参考官方文档,而是看 MR 的 Job Configuration,我们需要了解我们的 hadoop 集群的配置。
结合任务执行现象和 Druid 任务执行过程。修改如下参数,目的是单个 map 控制在 5min 内,单个 reducer 控制在 15min。
- 调整上游依赖表存储为 parquet 格式,并设置合并小文件,最终生成 500 个文件,根据流量波动,平均大小控制在 100 ~ 300M 之间。
- 调整 map 数,按照 256M 分片,500 个 map。(split 不能跨文件,所以 splieSize 在小于 256M 的情况下也会只产生一个 map,而不是两个 128M 文件合并成一个 map)。
- 调整 shuffle read 并发到 20,超时时间提高到 5 min,拉取同样的大小的文件,20 个线程拉取 500 个文件显然比拉取 24000 个文件执行效率高,并且网络 IO 开销小。
- reduce 阶段拉取到的 map 文件合并后占 jvm最大堆内存的比例由 0 调整到 0.1,大于才会溢写到磁盘。
- numBackgroundPersistThreads 按照官网建议设置为 1
- 调整摄入任务 targetPartitionSize=1200000,维持每个 segment 大小在官方建议的 500M~1G 之间,目的是为了 reduce 处理的数据更加均匀,避免数据不均匀引起的长尾任务。
需要调整的摄入任务参数如下
1 | "mapreduce.input.fileinputformat.split.minsize": 128000000 |
测试
测试受集群队列资源的影响比较大,所以可以使用预估时间来评估
1 | MR 耗时 = (map 数量 / map 并发数 * map 平均执行时间 + reducer 数量 / reducer 并发数 * reducer 平均执行时间 + 预估等待资源及开销时间) |
重新测试该天数据,启动了 500 个map,730 个 reducer。在白天队列资源紧张的情况下,三个 MR 总共执行了 74min,相比之前的 420 min 提升了5倍的效率,并且由于存储改成 parquet,存储资源也降低了 5倍。
因为 yarn 的容量调度基于内存来管理,内存决定着能申请到的 container 的数量,即并发度。在资源有限的情况下,使用更少内存做相同的事情会更高效。通过上面的公式也能看出来,在 reducer 数量不变或者减少的情况并且平均执行时间不变的情况下,增大 reduce 的并发数会提高的 MR 的效率。
由于设置了 targetPartitionSize,动态分区后,reducer 数量减少了一半,一开始直接调大 reducer memory -> 30G,jvm 最大堆内存设置为 30G。但是最终测试结果如下,可以看到简单的增大内存并不能加快执行效率,反而会由于并发降低拉长整个 MR 的执行时间。到底多少内存正好合适,除了不断测试,观察 jvm GC 情况也可以。
- 30G,25G → 50min。
- 21G,20G → 45min。
- 20G,18G → 56min,存在长尾任务 30min。
其实根据上述公式也能估算出来任务执行效率,白天执行,map 并发一般在 500 左右(即 yarn 子队列的最小资源保证),reducer 并发在 60 左右。
- 修改前 24000 / 500 * 0.5 + 960 / 60 * 16
- 修改后 500 / 500 * 0.5 + 730 / 60 * 16
结论
从修改参数后三周内摄入任务的执行情况来看。
- 在 6~ 9 点间执行情况差异不大,依然维持在 1.5h 左右。
- 在资源紧张+流量翻倍的情况下,摄入任务执行由原先的 6h → 2h,有2倍的性能提升,并且是在减少一半资源的情况下。
具体原因主要是因为减少了 map 数量引发的效应。
- map 阶段时间缩短一倍。
- shuffle read 阶段同样 4min ,修改后可以拉取到 2.4G 的数据,修改前只拉取到几十 m 的数据。
- reducer 数量降低一倍,且内存不变,平均执行时间维持在 15min,长尾任务在 18min 左右。