Spark Shuffle
前言
在学习很多大数据处理框架时,我们都会听到 Shuffle 。那么 Shuffle 到底是什么?为什么需要 Shuffle 的存在呢?
Shuffle 是什么
我们常理解的 shuffle 就是洗牌过程,将有规则的牌打乱成无规则的。但是在数据处理过程中,shuffle 是为了将无规则的数据洗成有规则的(将分布在不同节点上的数据按照一定的规则汇聚到一起)。
对于 MR 来讲,shuffle 连接了 map 阶段和 reduce 阶段。
对于 Spark 来讲,可以理解为 shuffle 连接了不同的 stage 阶段。
为什么需要 Shuffle
对于 MR 来讲,受限于其编程模型,reduce 阶段处理的必须是相同 key 的数据,所以必然需要 shuffle。
对于 Spark 来讲,其依靠 DAG 描述计算逻辑,其中没有宽依赖时,不会进行 shuffle。遇到宽依赖时,会划分 stage,从而需要 shuffle。这也是 Spark 相比 MR 更快的原因之一(因为 shuffle 阶段涉及大量的磁盘读写和网络 IO,直接影响着整个程序的性能和吞吐量)。
Spark Shuffle
Spark shuffle 的发展主要经历了以下几个阶段。
- HashShuffle。
- 引入 File Consolidation 机制,优化了 HashShuffle。
- SortMergeShuffle + bypass 机制。
- Unsafe Shuffle。
- 合并 Unsafe Shuffle 到 SortMergeShuffle。
- Spark 2.0 后,完全去除 HashShuffle。
shuffle 过程其实主要分为两个阶段,shuffle read 和 shuffle write。
- shuffle write 其实就是 map -> partition -> (sort) -> (combine)对数据按照指定规则进行分区排序预聚合,为下游 reduce task 处理做准备。
- shuffle read 其实就是 featch -> merge -> reduce ,对上游 map task 生成的数据进行拉取处理。我们可以从以下四个问题的角度来了解 shuffle read。
- 什么时候 fetch 数据?
- 以什么样的方式 fetch 数据,是边 fetch 边处理还是像 MR 一样等待一批数据准备好后在 fetch?
- fetch 的数据存放在哪里?
- 下游 reduce task 如何获取 fetch 的数据的存放位置?
下面就是讨论各种 shuffle 机制下是如何进行 shuffle read 和 shuffle write 的。以下讨论的假设前提是每个 executor 拥有一个 cpu core,每个 cpu core 上运行一个 task
HashShuffle
未经优化的 HashShuffle 流程如图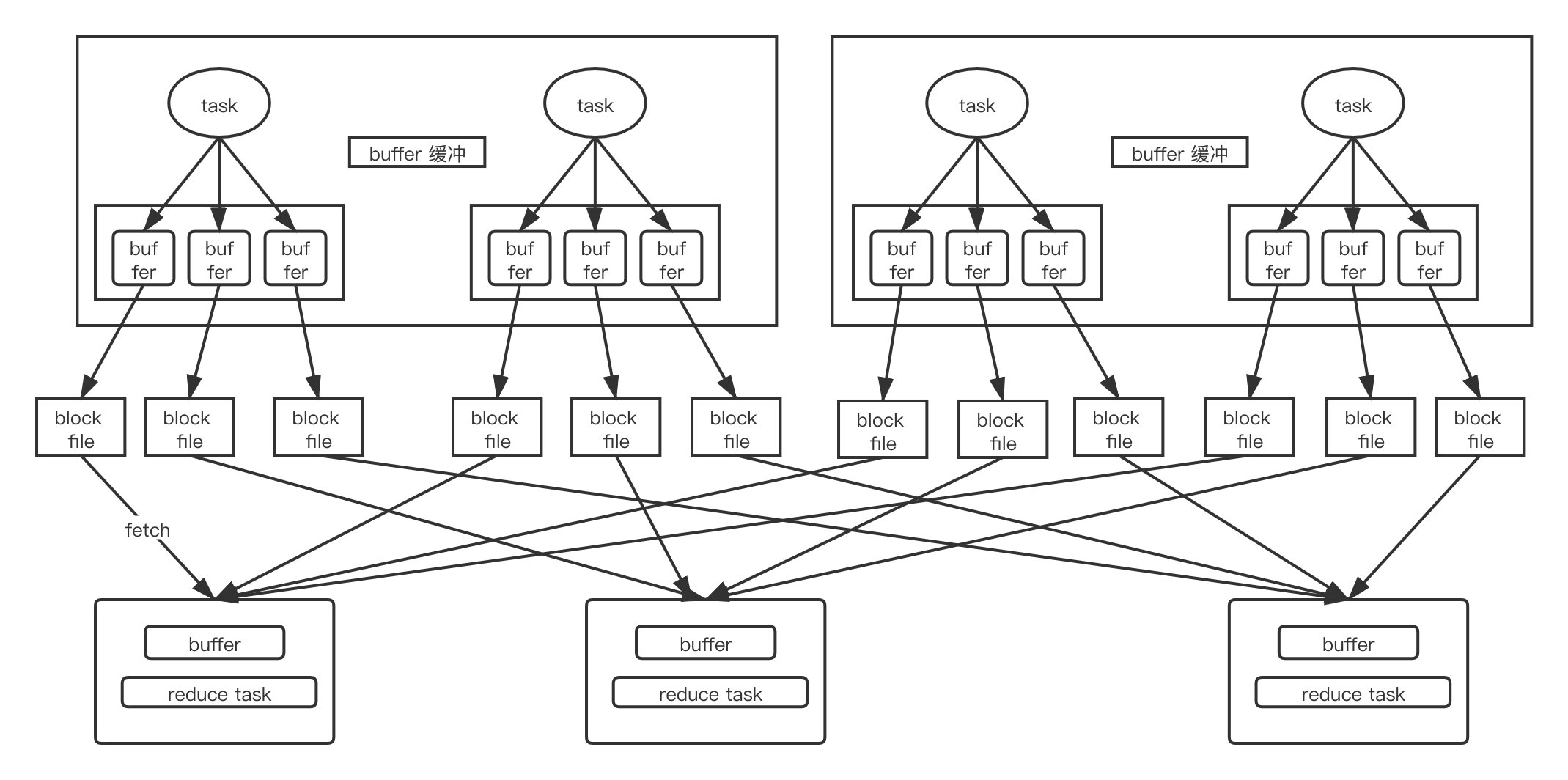
shuffle write
首先对数据按照 key 进行分区,相同 key 的数据会先保存在内存中,达到一定阈值后,溢写到磁盘文件,每个上游 task 相同 key 的数据一定会落到相同的磁盘文件中。
每个上游 map task 都要为下游所有的 reduce task 生成处理后的文件。所以产生的中间结果文件数量达到 M*R。碎片文件过多,对磁盘 IO 影响比较大。shuffle read
为了迎合 stage 的概念,可以理解为在上一个 stage task 都结束后,开始 shuffle read。在此过程中 reduce task 边 fetch 边处理数据,底层使用类 hash map - appendonly map 进行数据 fetch 处理结果的保存,阈值达到 70% spill 到文件。部分算子会选用 extrendappendonly map,本质是 appendonly map + sort 压实。
File Consolidation 优化后的 HashShuffle
引入 File Consolidation 优化后的 HashShuffle 后的流程如图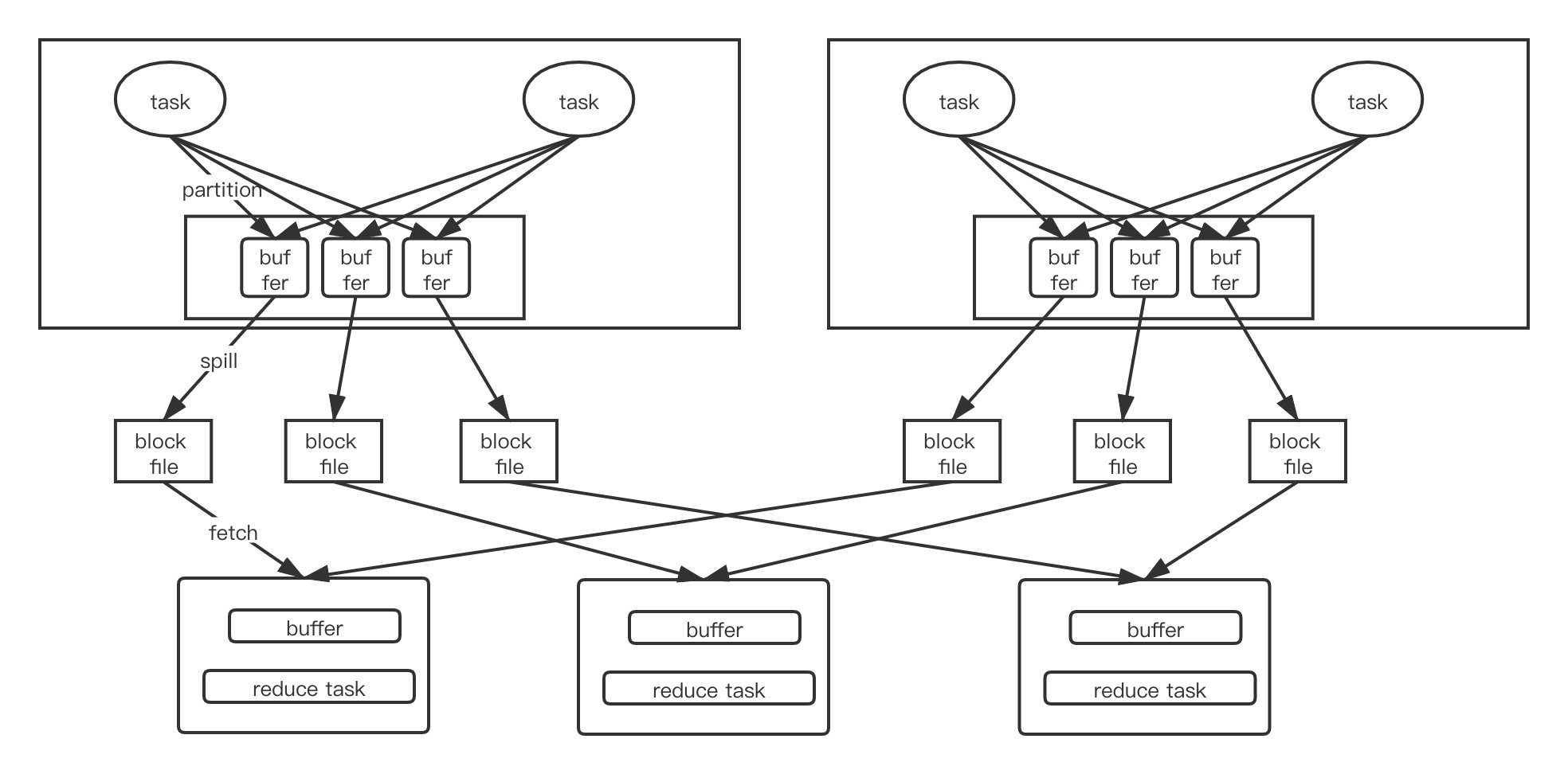
shuffle write
在图中也可以看出来,一个 cpu core 上多次运行的 task 最终只会生成一个磁盘文件。类似于组的概念。最终生成的磁盘文件数量为 core * R。在 executor 具有多个 cpu core 的时候可以提升很多性能。可以设置一下参数打开此机制1
spark.shuffle.consolidateFiles = true
shuffle read
shuffle read 过程没有太大改变
SortMergeShuffle
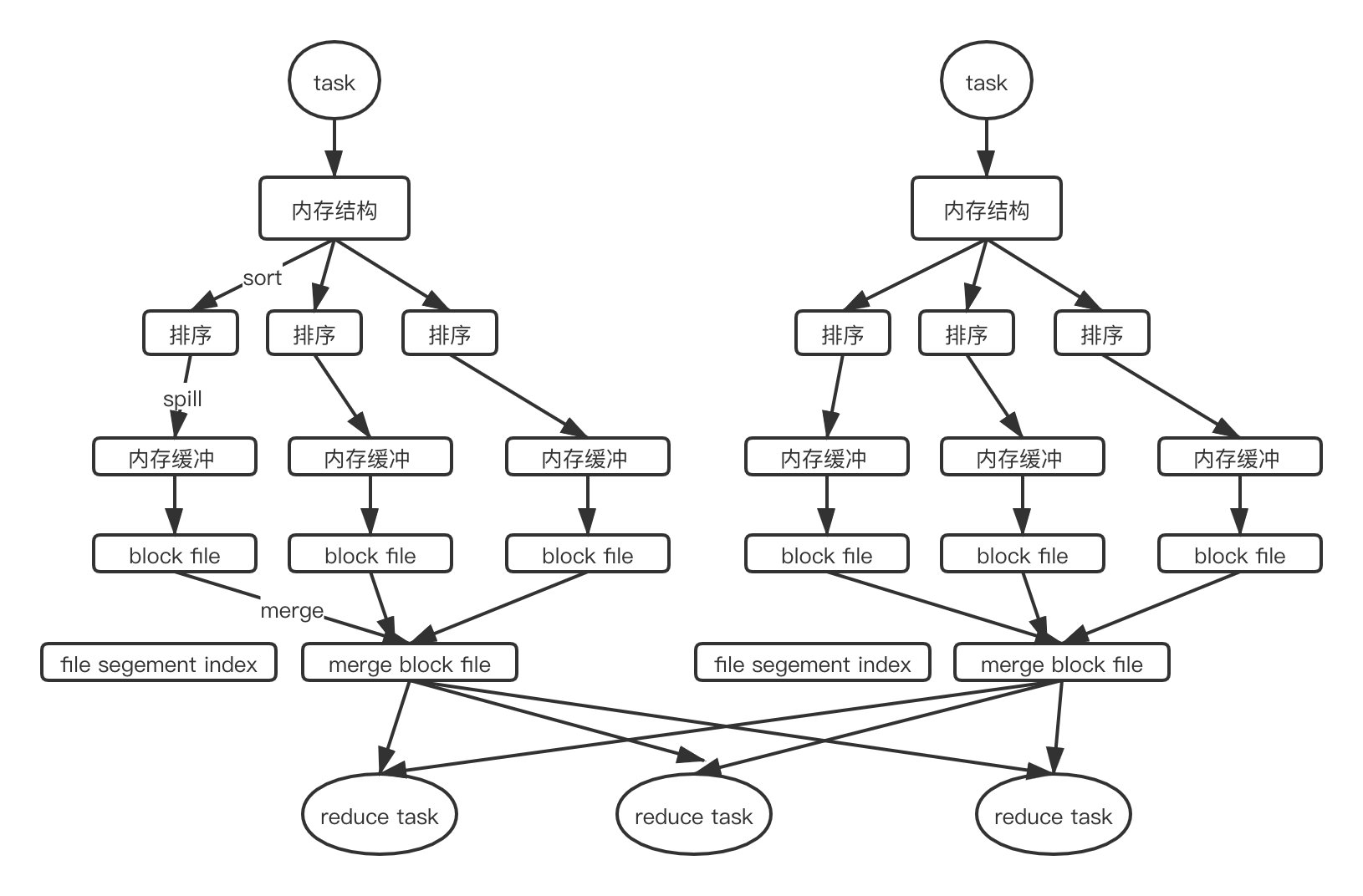
- shuffle write
在该模式下, 数据会先写入到内存数据结构中,边 map 边聚合,达到阈值后便会将数据溢写到磁盘并清空该数据结构。在写磁盘前,会先对数据进行排序,并分批写入磁盘文件,写入过程中,数据会先放进内存缓冲区,缓冲区满后在刷到磁盘,虽然减少了磁盘 IO ,但是此时最多可能会同时开 M*R 个buffer 缓冲区,对内存的压力也是比较大的。一般一个 shuffle map task 会发生多次溢写生成多个磁盘文件,最后会 merge 成一个磁盘文件,并生成一个文件段索引文件,为下游 reduce task 的拉取提供帮助。
生成磁盘文件数量就是 shuffle map task 的数量 - shuffle read
shuffle read 过程没有太大改变
bypass 机制
bypass 机制起作用下的 sortmerge shuffle。本质上和 hashshuffle 差不多,只是在 shuffle write 后 多了一层 merge。
当满足以下条件是,会舍弃掉 sort 阶段
shuffle map task 的数量小于 spark.shuffle.sort.bypassMergeThreshold
非聚合类的 shuffle 算子
shuffle write
shuffle map task 对数据按照 key hash 进行分区,并 spill 到文件。最终对每个 map task 生成的多个文件进行一次 merge。
Spark Shuffle 参数
通过上面也可以看到 shuffle 阶段涉及到大量的 spill 和开 buffer。如何减少 spill 次数降低磁盘 IO 呢,首先想到的就是调节 buffer 的大小,在内存资源充足的情况下,增大这个参数
- spark.shuffle.file.buffer - spark write task 溢写到磁盘文件时的内存缓冲区大小
- spark.reducer.maxSizeInFlight - spark read task 拉取数据时的 buffer 缓冲区大小
- spark.shuffle.memoryFraction - Executor 内存中,分配给 shuffle read task 进行聚合操作的内存比例,默认是 20%。
总结
很多文章说 Spark 内存计算是相比 MR 来说更快的原因之一,其实看过 shuffle 之后,会发现这个说法是不严谨的。程序只要运行就必须加载到内存中,MR 也是如此。Spark 更快速的原因是基于 DAG 构造了一个数据 pipeline,中间结果会优先放到内存,内存放不下了就会自动下放到磁盘,并且具体到各个算子,其会灵活的使用各种数据结构来优化内存的使用,减少 spill 到磁盘的个数。
以上只是批处理中的 shuffle,流式 shuffle 又是什么样子的呢,这是一个值得思考学习的问题。