Application UI - Monitoring and Instrumentation
前言
Spark Application UI 可以帮助我们直观的了解 Spark 的执行过程,作业占用的 CPU,内存资源的多少,GC耗费的时间,Stage 是如何划分的,每个 Task 的执行时间等。像如果 Spark 作业执行时间过长,我们就可以去 UI 上查看到底是哪个 Task 执行占用时间最长,这个 Task 的操作是什么,进而找到问题并解决优化。
Application UI
Jobs Tab
Jobs 页面为我们提供了 Spark 应用程序中所有的 Job 摘要及其详情页。摘要主要展示一些高维度的信息,比如 Job 的状态,运行时长,当前进度,整体作业执行的时间线(event timeline)。你可以点击相应的 Job 查看该 Job 的更详细的信息,比如 DAG 视图及该 Job 划分出的 Stage。
本节中显示的信息是
User: 当前 Spark 作业的用户
Total uptime:Spark 作业目前执行的总时间
Scheduling mode:作业调度模式,比如 FIFO
Number of jobs per status:Job 的执行情况,Active, Completed, Failed
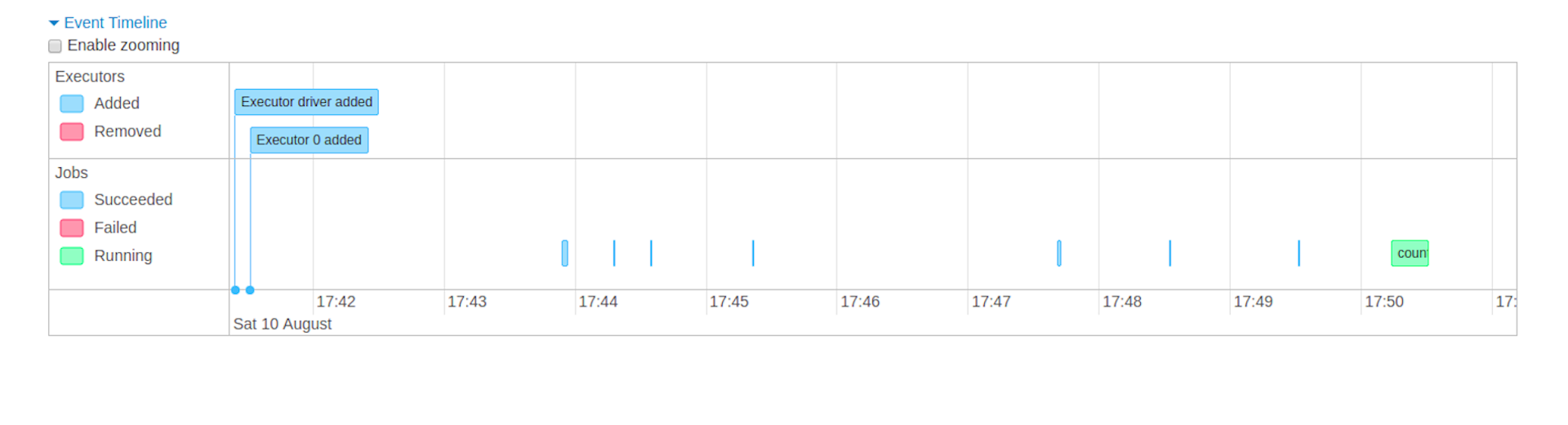
Event timeline:按时间顺序展示 executors 和 job 的 事件(及动作,比如 executor 的添加删除,一些算子的触发)
Details of jobs grouped by status: 以表格形式展现每个 Job 的详细信息,比如 Job ID,描述信息,提交时间,运行时长,Stage 的划分,包含的 tasks 的执行进度条。
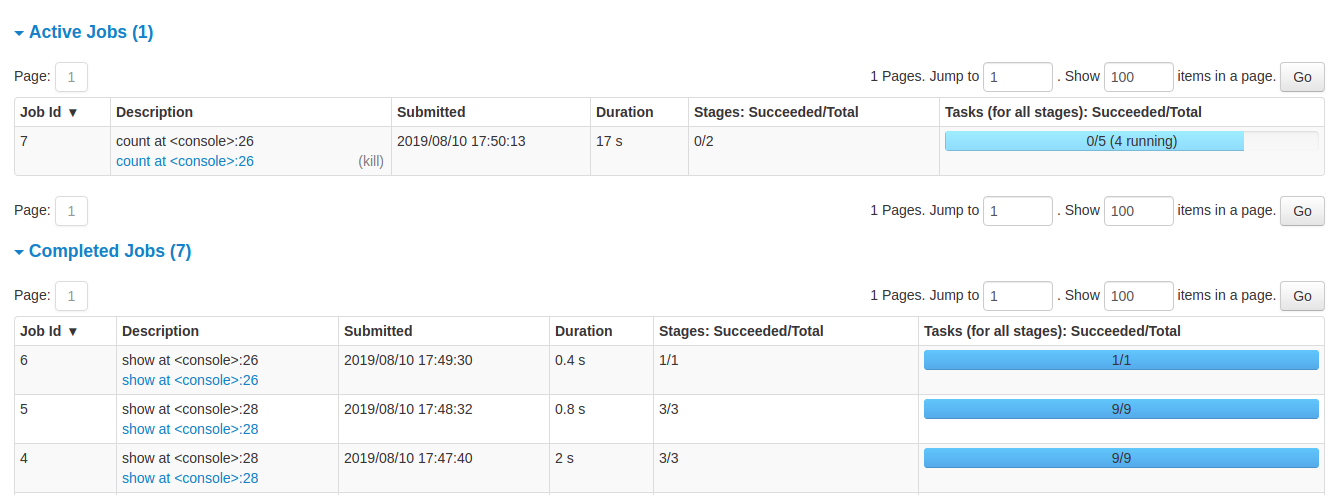
在 Job 的描述信息中,可以点击到 Job 的详情页。
Jobs detail
Job 详情页提供了特定 Job (由 Job Id 标识)更完善的信息
Job Status: (running, succeeded, failed)
每种状态的 Stage 数量 (active, pending, completed, skipped, failed)
关联的 SQL 查询
Event timeline:按时间顺序展示 executors 和 job 的 事件(及动作,比如 executor 的添加删除,一些算子的触发)
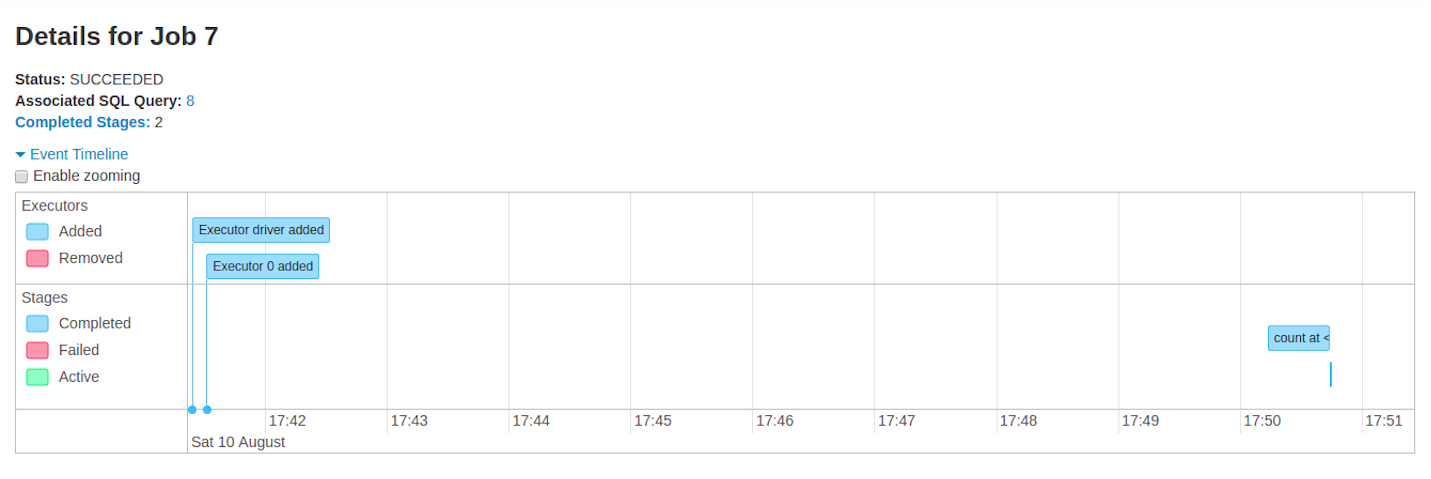
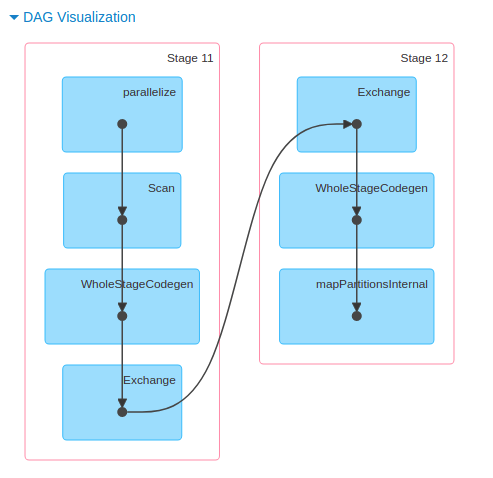
DAG 视图:该 Job 的 DAG 视图,顶点代表 RDD 或者 DF,边线代表应用在上面的操作。像里面的一些 WholeStageCodegen,其到底是啥嘞。
各个状态的 Stage 列表
- Stage ID
- Stage 的描述信息
- 提交时间
- Stage 的运行时长
- 该 Stage 包含的 Task 的运行时长
- Input,该 Stage 阶段 从 executor storage 中读取的字节数
- Output, 该 Stage 阶段 写 executor storage 的字节数
- shuffle read, shuffle read 阶段的字节和记录数,包含远端 executor 的读取
- shuffle write,shuffle write 阶段写磁盘的字节和记录数,目的是为了下一个 Stage 阶段开始的 shuffle read

Stages Tab
该页面显示所有 Job 中的 Stage 信息摘要。和 Job Tab 一样,一开始是各个状态的 Stage 的汇总。
在公平调度模式下,页面上还有一个 pools properties 的显示,这个是干啥的嘞?需要后面了解下
下面就是各个状态的 Stage 的详细信息,和 Job 一样,唯一标识ID,描述信息,提交时间,运行时长,Tasks 的执行进度条,点击描述信息中链接可以查看该 Stage 中 Task 的详细信息。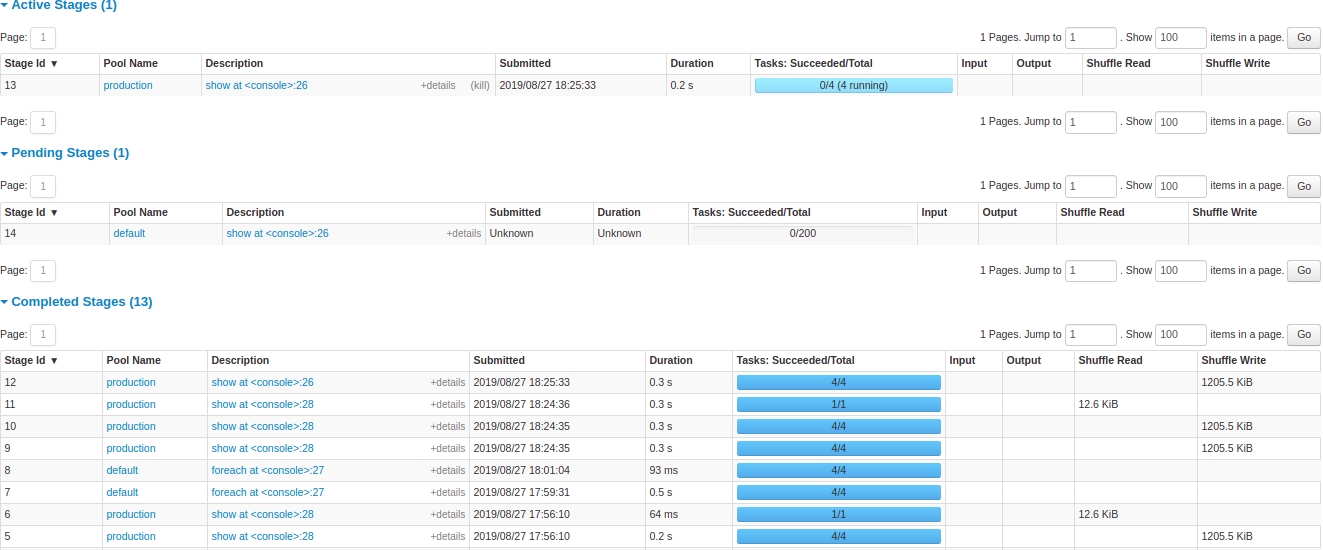
Stage detail
页面最开始显示的摘要信息,该 Stage 的 DAG 视图
- 所有 Task 执行的时间
- 本地化级别
- Shuffle Read
- 关联的 Job,这个 Stage 是哪个 Job 划分出来的
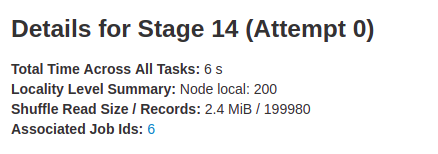
下面是该 Stage 中 Task 运行的一些指标
- Tasks deserialization time,Task 在反序列化上耗费的时间,如果该部分耗时较长,则可以选择更高效的序列化方法,比如 kyro
- Duration of tasks,Tasks 运行的时长
- GC time,GC 时间,如果耗费时间比例比较大或者发现频繁GC,可以适当调高 executor memory 的比例。
- Getting result time,Worker 获取到 Tasks 的结果集的时间
- Result serialization time,Task 计算出的结果集序列化耗费的时间
- Scheduler delay,等待调度执行的时间
- Peak execution memory,shuffle,聚合等阶段生成的数据对象占用的最大内存
- Shuffle Read Size / Records
- Shuffle Read Blocked Time,task 等待远端 executor 读取数据的时间
- Shuffle Remote Reads,从远端读取的数据字节,这里和上面几个属性,可以去了解下 RDD 的最佳计算结点位置,及本地化级别
- Shuffle spill (memory), 反序列化 Shuffle Data,shuffle read
- Shuffle spill (disk),序列化数据数据到磁盘,shuffle write
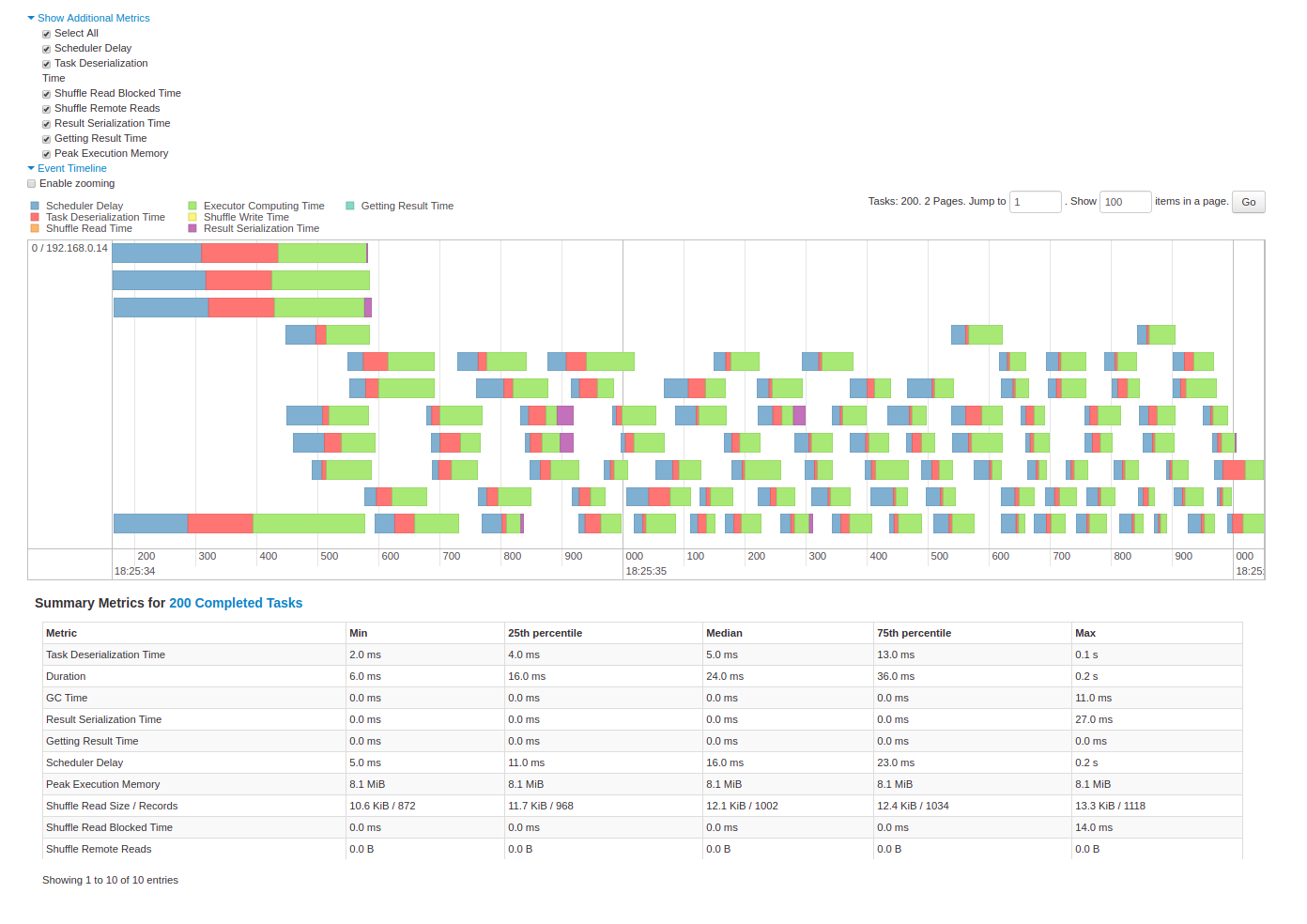
最下面展现了 Task 列表,emnn,里面的信息应该一目了然了。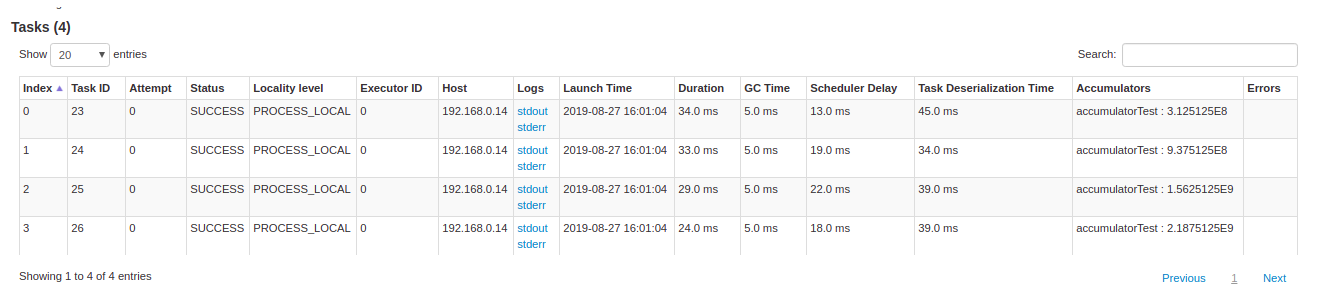
Storage Tab
在 Storage 界面可以看到持久化的 RDD 信息。spark-shell 中执行以下代码
1 | scala> import org.apache.spark.storage.StorageLevel._ |
现在在页面上就可以看到持久化的 RDD 和 DataFrame。
点击 RDD Name 可以看到缓存的 RDD 的详细信息,比如分区数, 每个分区下 block 的持久化级别和大小。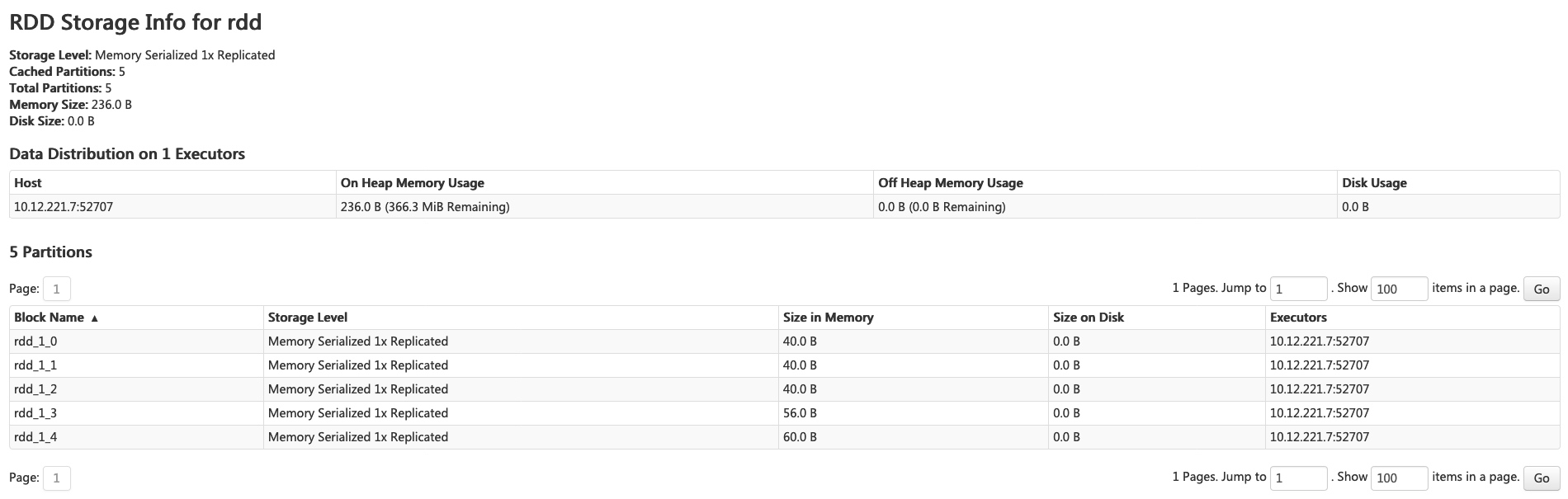
Environment Tab
该页面显示一些环境变量和配置值,包括 JVM,Spark,和一些系统属性。相对重要的是 Spark Properties,在这里可以看我们的配置是否生效。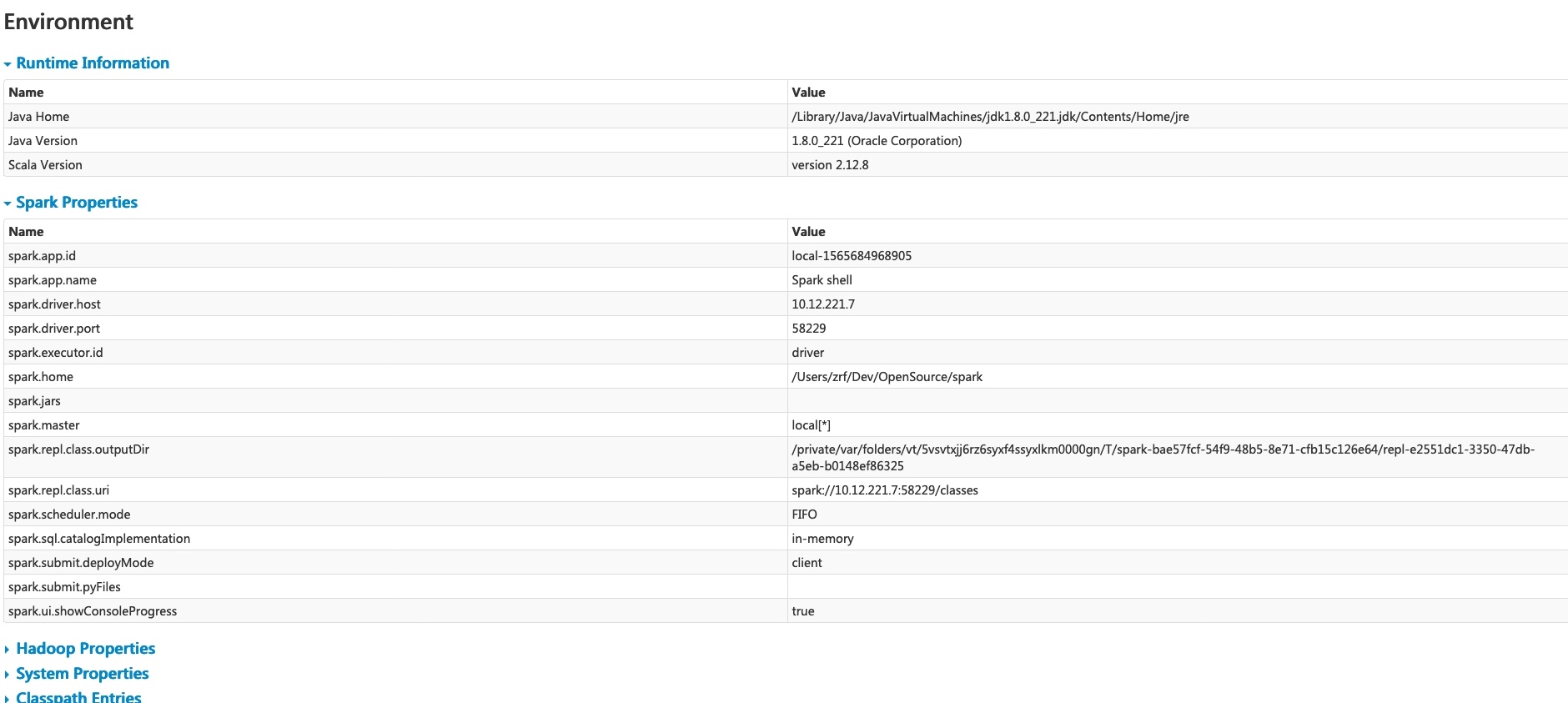
Executors Tab
Executors Tab,名如其意,会显示该 Spark Appliaction 关联的 Executor 的信息。经常关注的是 executor 的资源信息,比如内存,CPU core,GC 时间,shuflle 阶段数据的大小。当然也可以直接查看日志(页面上有 stderr,stdout)。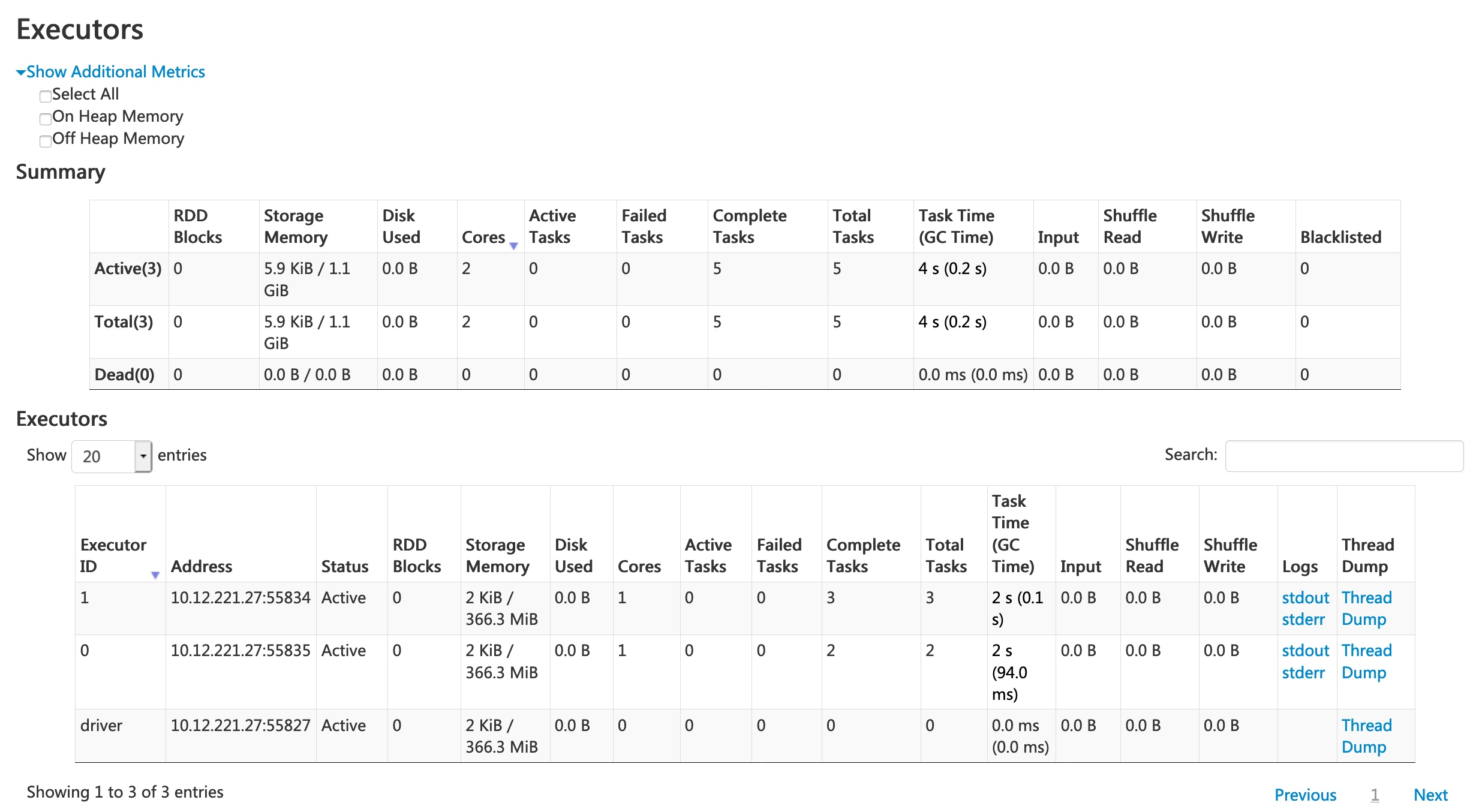
SQL Tab
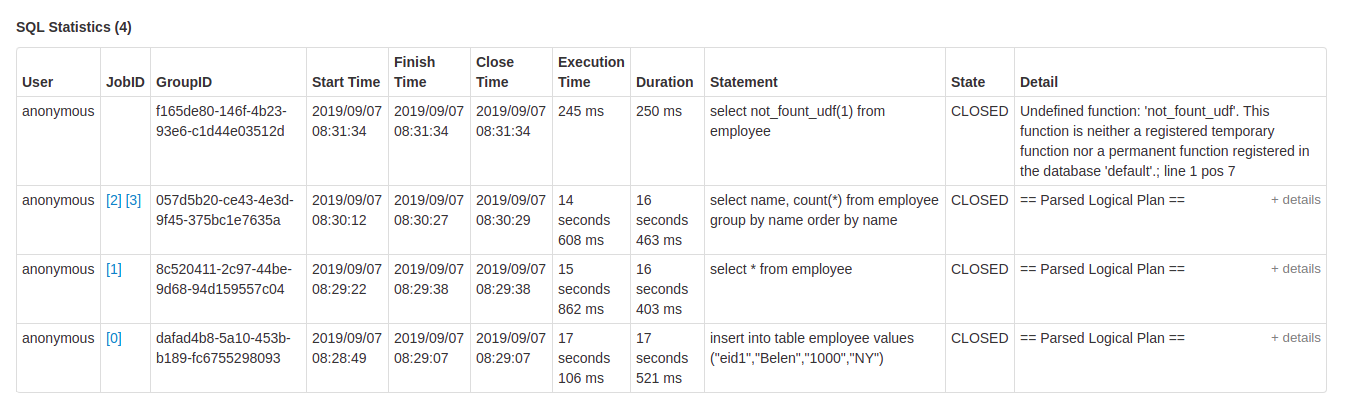
如果你的应用程序执行的是 sql 而非 Spark DSL。该页面会展示 Spark sql 执行相关的信息。,比如该 sql 执行各阶段的提交时间,运行时长,关联的 Job,查询的逻辑计划和物理计划。下面我们运行一个例子来说明 SQL Tab。
1 | scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name") |
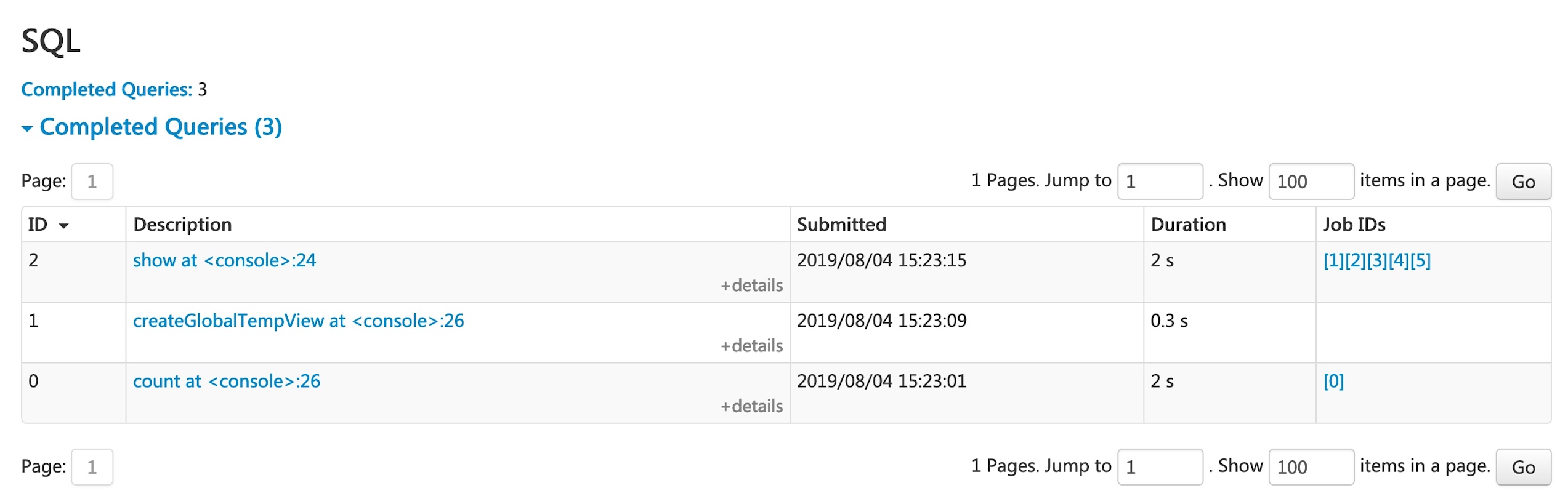
上图中就展现了运行了 sql 的操作列表。点击 Description 描述信息可以看到该 sql query 的 DAG 图。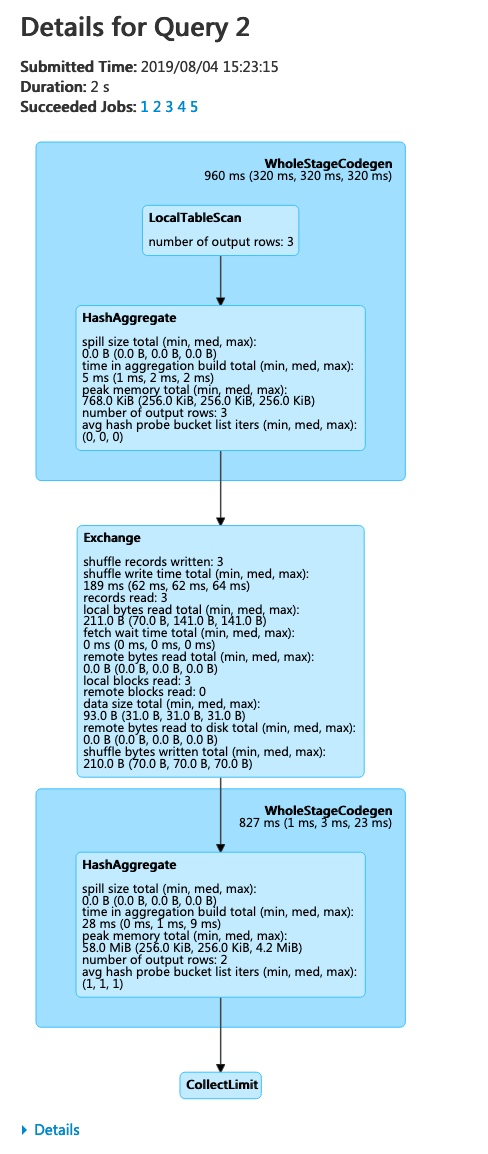
点击 details,可以看到该 sql query 的执行计划。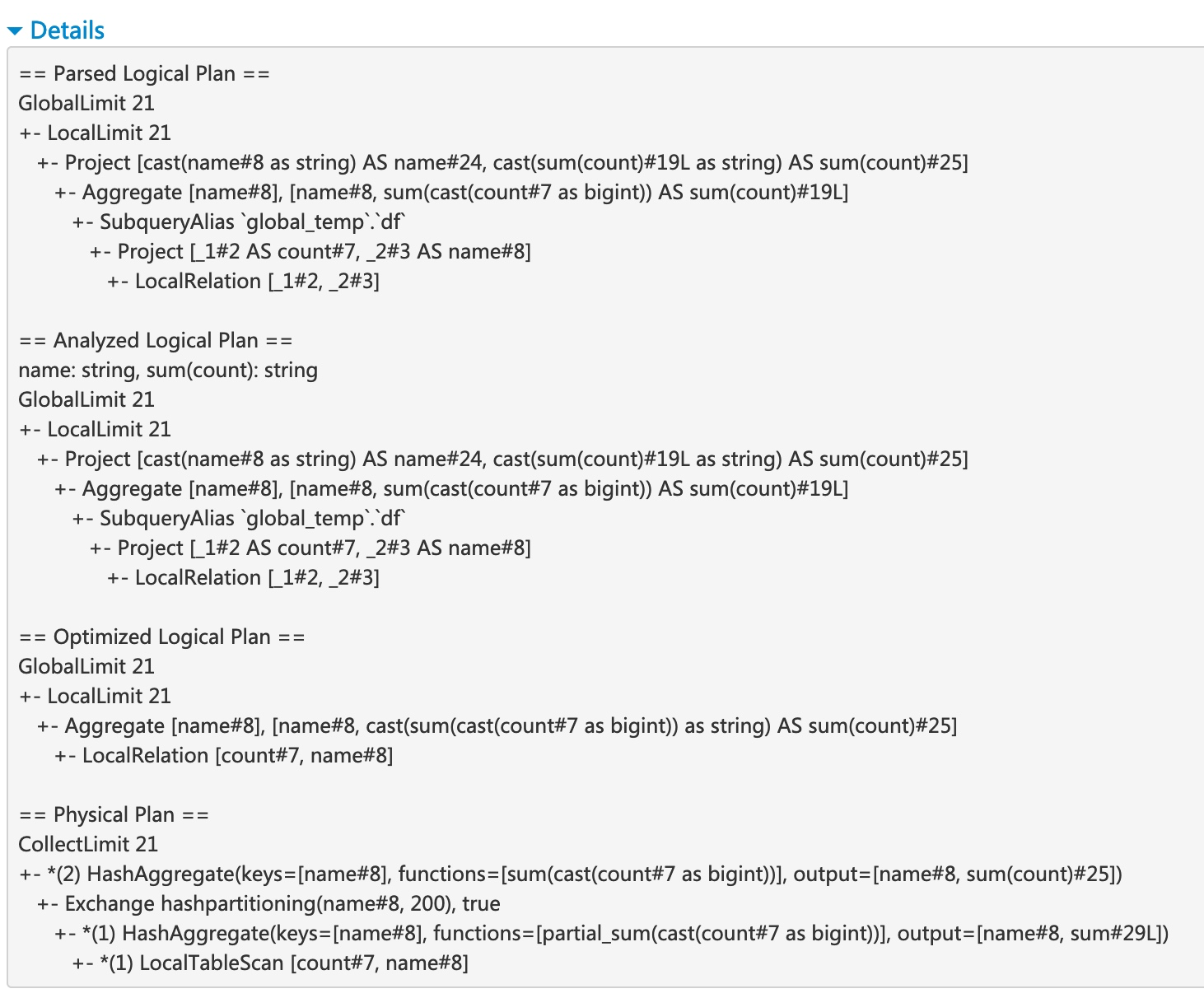
在 sql query 生成的 DAG 图中有 stage 阶段中更为详尽的信息,比如上面的 shuffle records written,records read,number of output rows等。
Streaming Tab
关于Spark Streaming 应用程序的页面,主要展示数据流中每一个 micro-batch 的调度延迟和处理时间,方便查找问题
JDBC/ODBC Server Tab
Spark SQL 还可以使用其JDBC / ODBC或命令行界面充当分布式查询引擎。在这种模式下,最终用户或应用程序可以直接与 Spark SQL 交互并运行 SQL 查询,而无需编写任何代码。
该页面主要用来展示 Spark 直接充当分布式查询引擎时的信息。