Prometheus + Grafana 监控 - Kafka
前言
最近工作中越来越感受到监控对于查找问题的重要性,一个完备的链路监控对问题定位和趋势分析提效非常高。比如一条实时数据流,从数据采集到消费到入库各个阶段都有一些可观测性的指标(binlog 采集延迟,kafka-lag,读写 QPS,max-request-size,offset 趋势)。如果 kafka-lag 比较小并且 topic 写 QPS没打太高,但是数据有延迟,这里大概率就是上游采集的问题。
这里借用 prometheus 官网的话介绍监控的作用。
- 长期趋势分析:通过对监控样本数据的持续收集和统计,对监控指标进行长期趋势分析。例如,通过对磁盘空间增长率的判断,我们可以提前预测在未来什么时间节点上需要对资源进行扩容。
- 对照分析:两个版本的系统运行资源使用情况的差异如何?在不同容量情况下系统的并发和负载变化如何?通过监控能够方便的对系统进行跟踪和比较。
- 告警:当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从而能够对问题进行快速的处理或者提前预防问题的发生,避免出现对业务的影响。
- 故障分析与定位:当问题发生后,需要对问题进行调查和处理。通过对不同监控监控以及历史数据的分析,能够找到并解决根源问题。
本系列主要用来记录工作中常见系统的监控实现,指标含义以及如何通过监控定位问题并在相关任务挂掉后如何和给下游业务一个较准确的预估恢复时间。大部分借助开源实现。
Prometheus
安装
直接 brew 安装启动即可,也可以参考 prometheus 中文文档 通过预编译包安装。
1 | brew info prometheus |
在 prometheus.yml 里面配置抓取的 job。 需要注意一下,如果是 mac os 的话,Prometheus 默认配置文件地址为 /usr/local/etc/prometheus.yml。
使用
安装完成后,可以打开 http://localhost:9090/ 查看 Prometheus UI。可以在 Status-Targets 里面找到已经启动抓取的 exporter。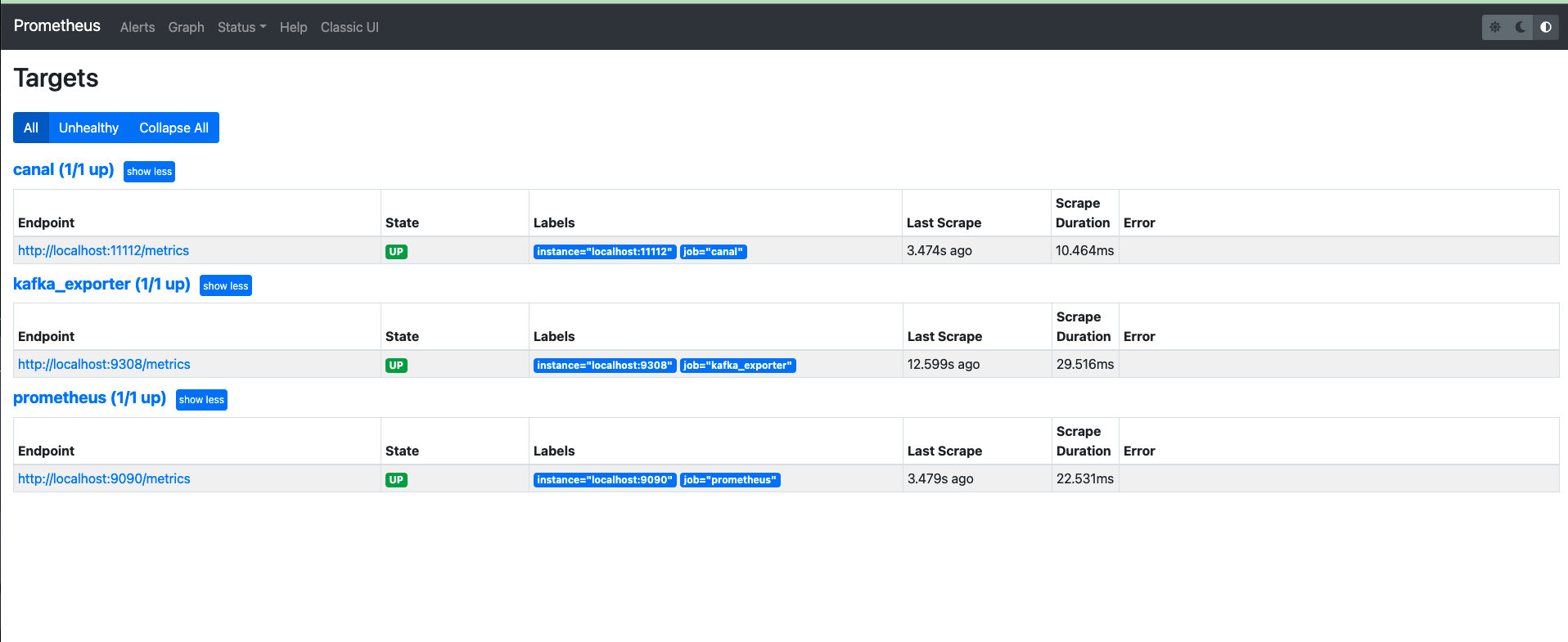
Prometheus 大概的流程如下。更多的信息可以查看官方文档。其中 PromQL 以及 metric 的格式需要重点了解下,以后查询 metrics,配置 Grafana DashBoard 都会用到。
- Prometheus server 定期从配置的 job 拉取 metrics。
- Prometheus 将拉取的 metrics 信息存储到本地,记录新的时间序列。如果触发定义好的 alert.rules,AlterManager 会向用户发送报警。
需要注意的地方
使用 brew service 无法启动服务的话,可以去查看 xx.plist 文件中的 log 路径找具体错误。我这里就是碰到 9000 端口被其他代理服务占用,然后 prometheus 一直在 error 状态。
1 | $ brew services list | grep prometheus |
Grafana
安装
1 | brew info grafana |
使用
打开 http://localhost:3000/,查看 Grafana UI,默认账户名密码是 admin/admin。使用流程和普通写程序差不多,全套 CURD。
- 配置 DataSource
- 配置 DashBoard,直接 load 模板或者自己通过 PromQL 配置。
- 配置告警规则
kafka_exporter
kafka_exporter 用来收集 Topic,Broker,ConsumerGroup 的相关信息,可以无缝对接 Prometheus 和 Grafana,使用起来比较方便。
安装
查看对应的 github 项目 kafka_exporter。在 release 页面中下载适合 mac os 的包(kafka_exporter-1.3.1.darwin-amd64.tar.gz
)。
1 | wget https://github.com/danielqsj/kafka_exporter/releases/download/v1.3.1/kafka_exporter-1.3.1.darwin-amd64.tar.gz -P /usr/local/Cellar/kafka_exporter && cd /usr/local/Cellar/kafka_exporter |
使用
启动 kafka 集群,执行启动脚本。
1 | nohup kafka_exporter --kafka.server=localhost:9092 >> kafka_exporter.log 2>&1 & |
修改 prometheus.yml,加上 kafka_exporter 的 job。默认端口是 9308。
1 | global: |
查看 prometheus ui,可以观察到已经启动抓取的 job。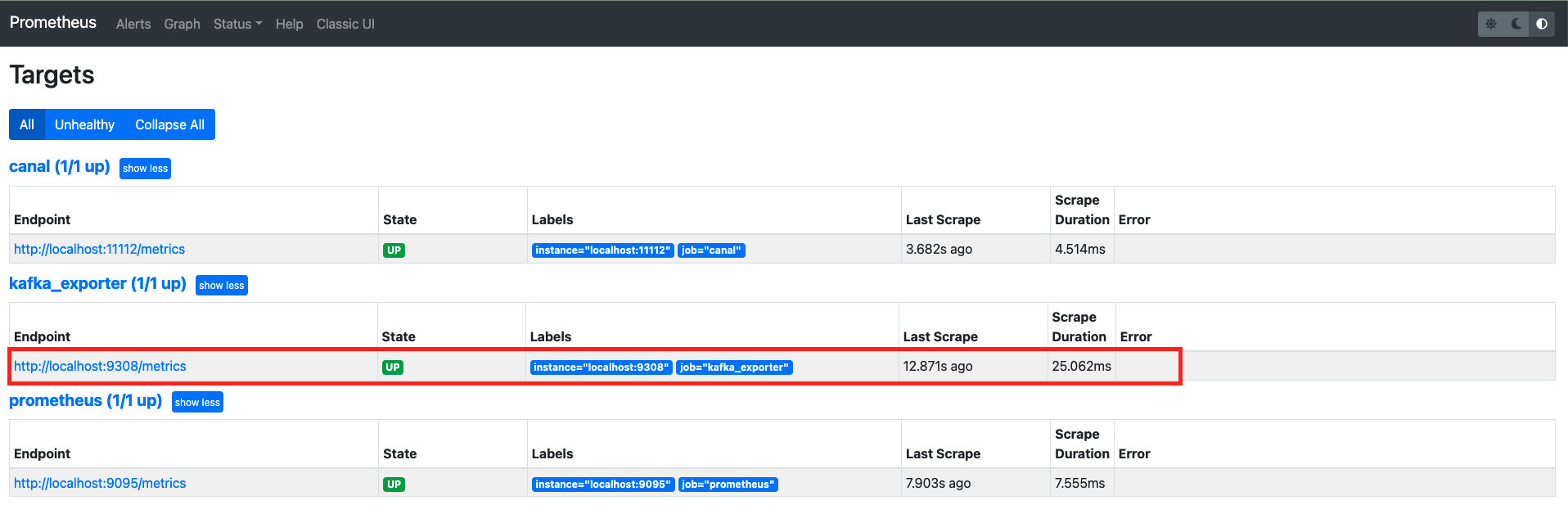
访问上图中的 Endpoint 地址(默认是 http://localhost:9308/metrics),可以查看已经抓取到的指标。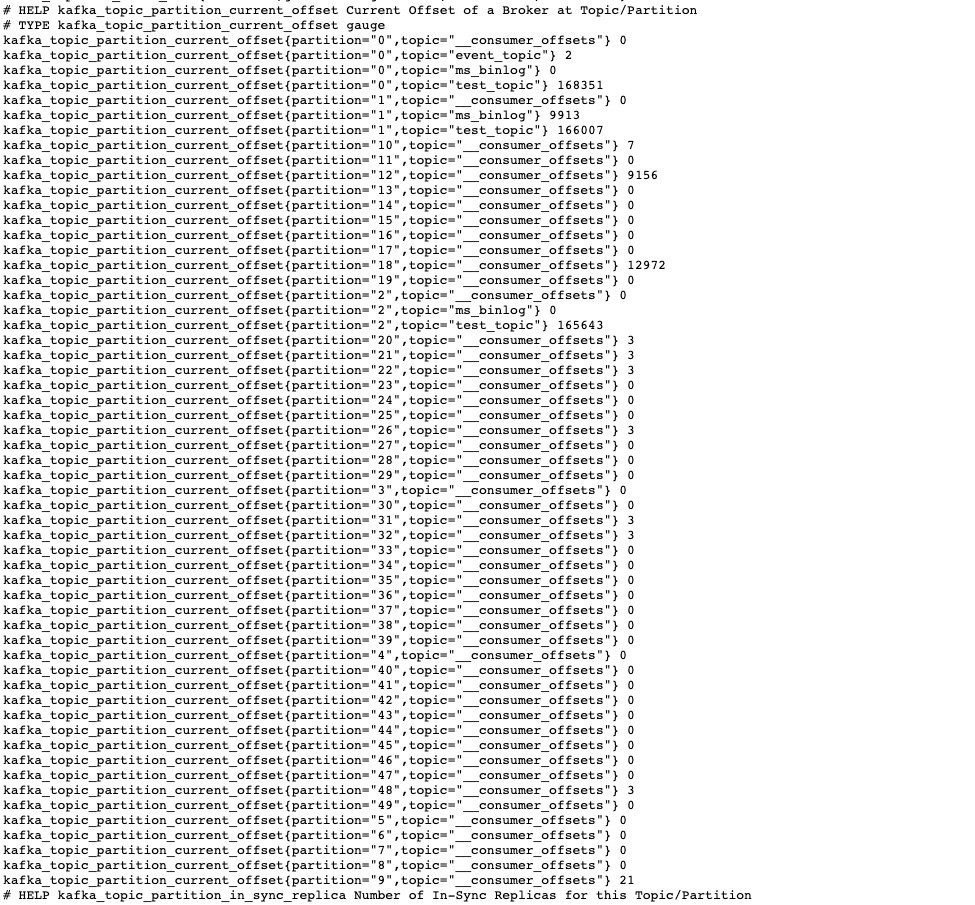
指标列表
参考 kafka_exporter 的 Readme。
| Metrics | Description |
|---|---|
| kafka_brokers | kafka 集群的 broker 数量 |
| kafka_topic_partitions | kafka topic 的分区数 |
| kafka_topic_partition_current_offset | kafka topic 分区当前的 offset |
| kafka_topic_partition_oldest_offset | kafka topic 分区最旧的 offset |
| kafka_topic_partition_in_sync_replica | 处于同步过程中的 topic/partition 数 |
| kafka_topic_partition_leader | topic/partition leader 的 broker id |
| kafka_topic_partition_leader_is_preferred | topic/partition 是否使用 preferred broker |
| kafka_topic_partition_replicas | topic/partition 的副本数 |
| kafka_topic_partition_under_replicated_partition | partition 是否处于 replicated |
| kafka_consumergroup_current_offset | kakfa topic 消费者组的 offset |
| kafka_consumergroup_lag | kakfa-lag 消费延迟 |
遗留问题
如何使用 kafka_exporter 监控多集群?启动多个 kafka_exporter 实例还是有其他方式。
Grafana 看板配置
关于 kafka,我们比较关注的是集群 broker 数量,topic 可用分区数,读写 QPS,partition offset,kafka-lag,吞吐量。
如果是第一次接触 Grafana 的话,建议直接导入模板,然后在模板基础上模仿修改最终达到自己想要的效果。Grafana DashBoard。这里使用的模板是
7589。
tips:在使用 prometheus 作为数据源的时候,grafana 的 query 配置其实就是 promQL+指标+。比如(sum(kafka_topic_partitions{instance=“$instance”,topic=“$topic”}))
创建 DashBoard,配置数据源,导入模板。


添加 consumergroup variable,方便查看每个消费者的 lag 和 offset 趋势。
参考模板的几个 variable 的配置。job -> prometheus job。instance -> kafka_exporter 实例。topic -> kafka 主题。consumergroup -> 消费者组。关于一些变量命名可以直接访问 http://localhost:9308/metrics 查看。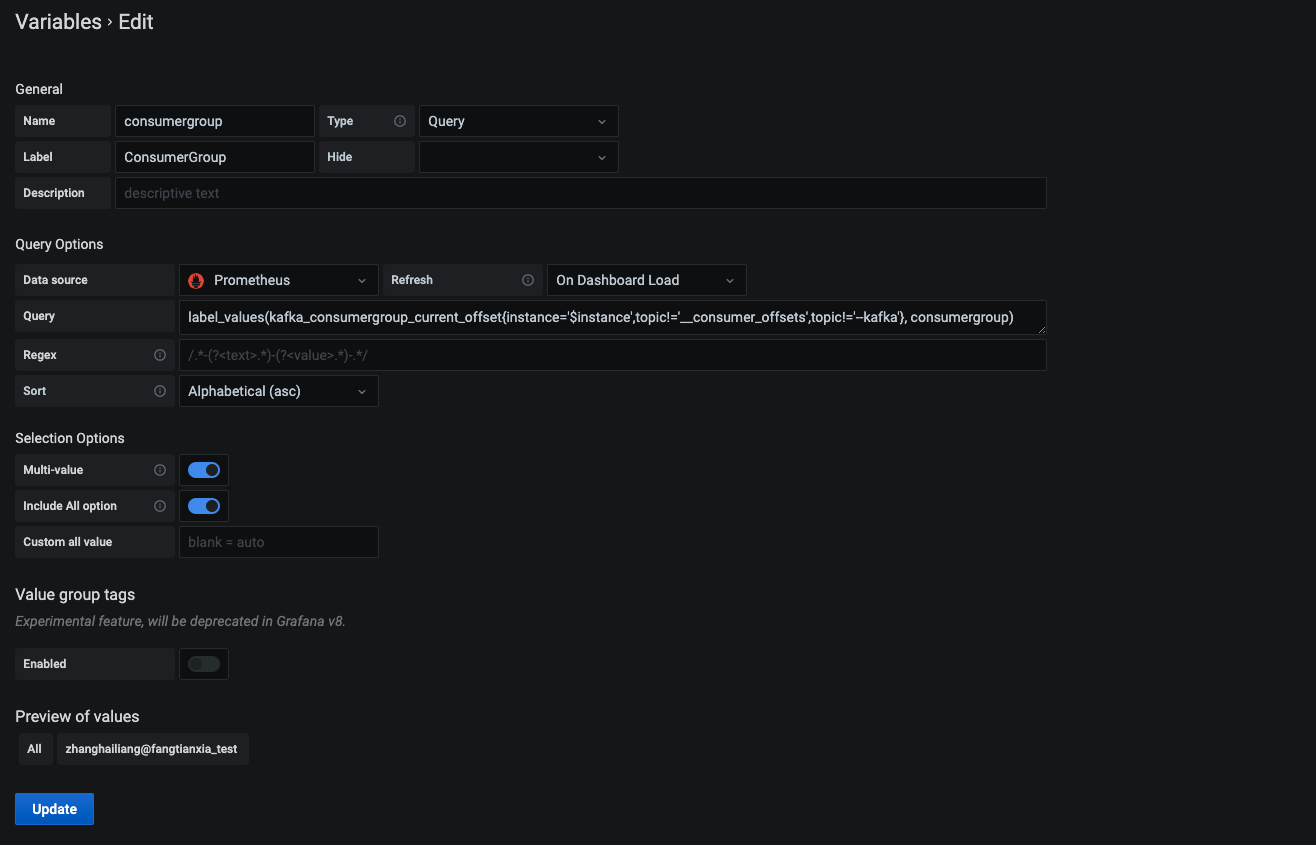
添加 broker,partition,吞吐量的 stat panal。
broker,partition 的指标 kafka_exporter 本身已经抓取到。
吞吐量其实就是 kafka_topic_partition_current_offset 的增长和 kafka_consumergroup_current_offset 的增长,这里使用 rate 来计算平均增长速率。配置 kafka-lag panal 和报警。
使用 kafka_consumergroup_lag。
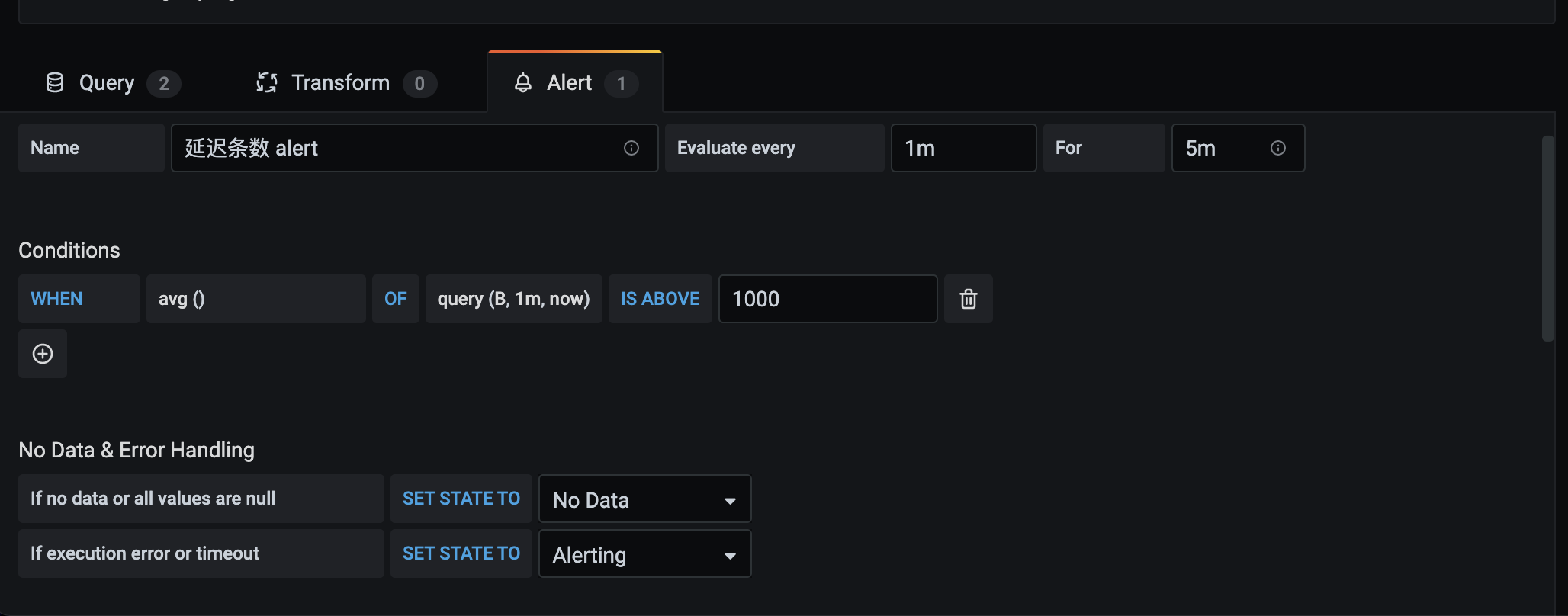
配置 Alert 的时候会报错template variables are not supported in alert queries,这是因为 alert 不支持带变量的 metrics。添加 query,设置一个常量,并且设置为不可见即可。然后使用该不可见指标配置报警规则。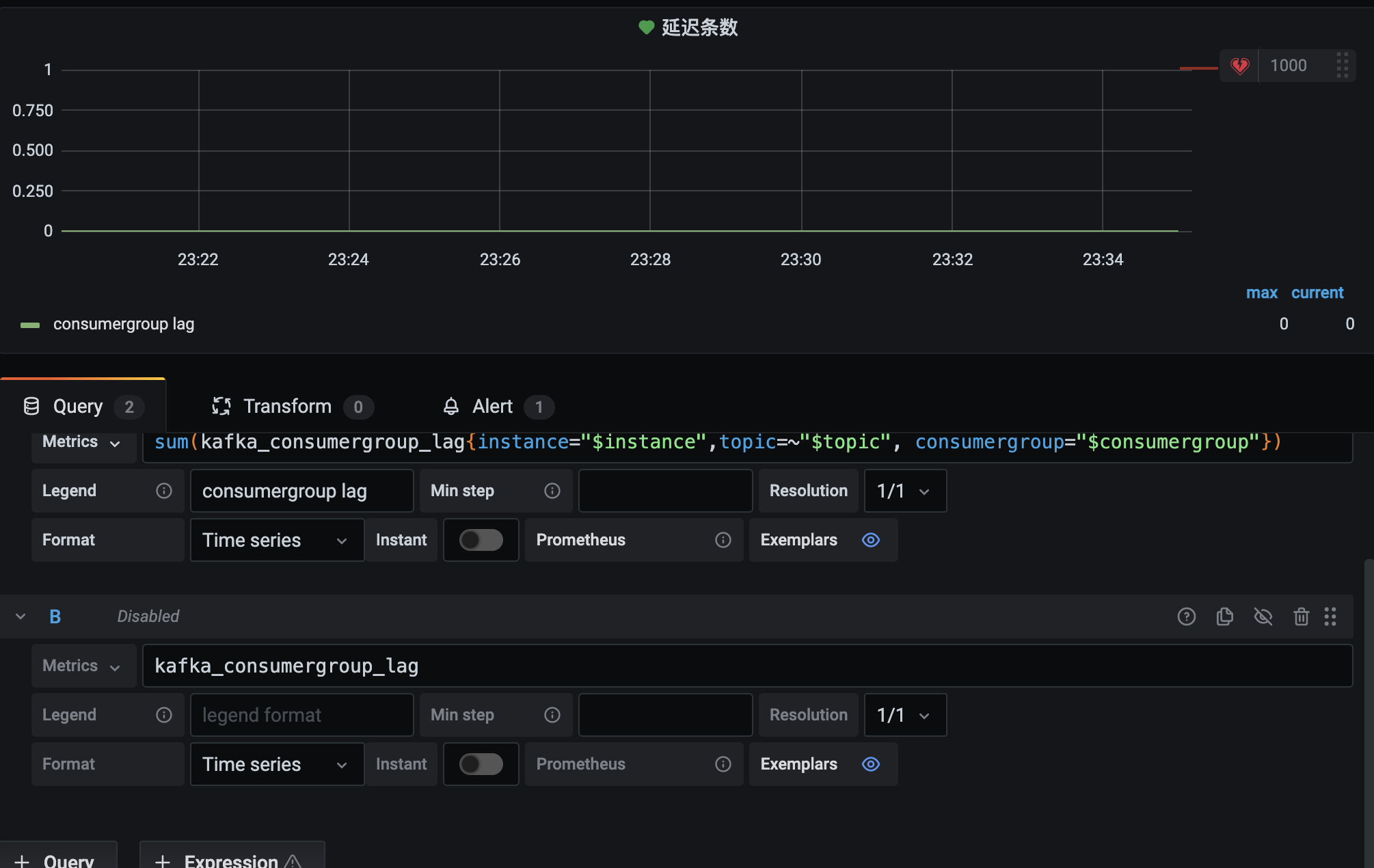
配置 offset 趋势。
配置 topic 的读写 QPS。
和吞吐量的算法一样。配置 partition offset。
看板配置完成后,可以往 kafka topic 写入数据并启动 kafka-console-consumer 观察。因为我本地配置了 canal,所以直接 create_time + 1 触发了 binlog 到指定 topic。最后整体看板如下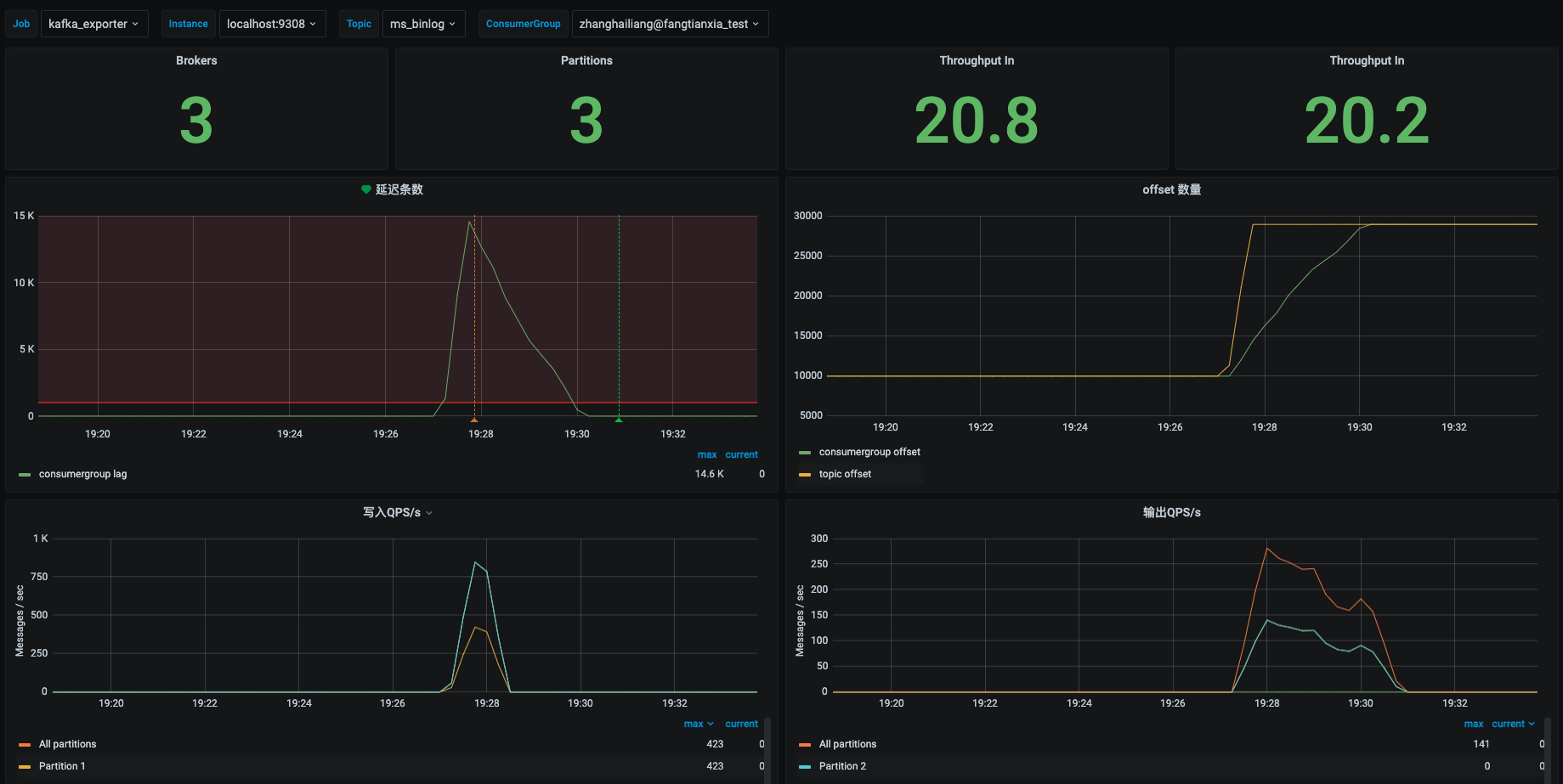

监控分析
kafka 广泛应用于实时作业中,所以对其的监控报警是必要的。上面配置的看板对于问题查看分析有什么作用呢?下面举几个典型的例子。
kakfa topic 消费堆积
kafka-lag 是比较重要的性能指标。一般实时流任务的延迟,首先考虑到的就是消费堆积,此时需要查看是否刷数场景或者业务高峰期造成的短期堆积,是否需要临时加大消费者资源防止对下游业务使用造成影响。kafka-lag 恢复时长估计
可以观察 consumergroup offset 的上升趋势,计算处理速度。binlog 端到端延迟判断
需要结合 binlog 监控。如果没有 kafka-lag 且写 QPS 正常,一般是 canal 采集的问题。如果存在 kafka-lag 并且写入 QPS 比往常高很多,就要考虑刷数场景造成的堆积,进而产生 binlog 端到端延迟。topic 分区是否均匀
观察 partition offset 和分 partition 写入 QPS。如果某个分区写入数据量很少,那么需要考虑分区 key 是否合理。不合理的分区对下游消费也会产生性能影响。