druid 问题记录
前言
日常工作中采用 Druid 做流量日志分析。因为是刚接触,所以在离线/实时数据摄入过程中经常会碰到一些问题,本文主要用来记录这些问题及一些思考。
问题记录
实时摄入任务 offset 获取失败
完整错误如下。实时摄入脚本在一周内发生了三次这样的错误,属于偶发错误,前两次伴随着 coordinator 节点的重启,当时查看任务日志发现请求 coordinator 接口失败,以为是任务恰好在该节点上,所以发生错误。
最后一次发生没有节点重启,当时查看了 issue#7926,说是 0.16 之前的版本在某些竞态条件下会拿到 start 类型的 offset,而 druid 默认采用 end 类型,在做 minus 减法时,发现 SeekableStreamEndSequenceNumbers 和 SeekableStreamEndSequenceNumbers 类型不匹配,由此产生异常。
至于是何种条件导致拿到了 start 类型的 offset,看了下源码也没看明白,留作疑问。这里个人也有个疑问,既然默认采用了 end 类型,并且 kafka 和 kinesis 使用的方法大体一致,为什么此处不合并成一个 SeekableStreamEndSequenceNumbers 类呢?
1 | "timestamp": "2021-08-05T03:44:17.495Z", |
后续又看了下此问题,因为摄入任务参数中设置了 resetOffsetAutomatically 为 true,屏蔽了底层问题。修改后,报错如下。
1 | "timestamp": "2021-10-04T06:40:40.607Z", |
查看 kafka offset 信息,报错中的 offset 是三天前的,而 topic 只保留 24h 数据,同时查看 overload 日志,发现 not updating metadata 的日志,看起来是 druid_datasource 的元数据没更新导致,查看源码,发现如果是更新失败的话,还会有 Not updating metadata, compare-and-swap failure 的错误,但是这里没有。好嘛,一个问题变成两了,因为日志留存问题,需要等下次报错再查了。
- 为什么今天的摄入任务会试图读取几天前的 offset ?
- 为什么设置了自动 reset,在重置的时候会一直报错?
实时摄入任务直接切换 source topic 引发的 segment publish failed
完整错误如下。显示 segemt 发布失败。
1 | "errorMsg": "java.util.concurrent.ExecutionException: org.apache.druid.java.util.common.ISE: Failed to publish segments because of [java.lang.RuntimeException: Aborting transaction!].\n\tat com.google.common.util.concurrent.AbstractFuture$Sync.getValue(AbstractFuture.java:299)\n\tat com.google.common.util.concurrent.AbstractFuture$Sync.get(AbstractFuture.java:286)\n\tat com.google.common.util.concurrent.AbstractFuture.get(AbstractFuture.java:116)\n\tat org.apache.druid.indexing.seekablestream.SeekableStreamIndexTaskRunner.runInternal(SeekableStreamIndexTaskRunner.java:767)\n\tat org.apache.druid.indexing.seekablestream.SeekableStreamIndexTaskRunner.run(SeekableStreamIndexTaskRunner.java:235)\n\tat org.apache.druid.indexing.seekablestream.SeekableStreamIndexTask.run(SeekableStreamIndexTask.java:168)\n\tat org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner$SingleTaskBackgroundRunnerCallable.call(SingleTaskBackgroundRunner.java:413)\n\tat org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner$SingleTaskBackgroundRunnerCallable.call(SingleTaskBackgroundRunner.java:385)\n\tat java.util.concurrent.FutureTask.run(FutureTask.java:266)\n\tat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\n\tat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\n\tat java.lang.Thread.run(Thread.java:748)\nCaused by: org.apache.druid.java.util.common.ISE: Failed to publish segments because of [java.lang.RuntimeException: Aborting transaction!].\n\tat org.apache.druid.segment.realtime.appenderator.BaseAppenderatorDriver.lambda$publishInBackground$8(BaseAppenderatorDriver.java:602)\n\t... 4 more\n" |
还原下问题场景,实时摄入脚本一开始采用测试 topic 源,和线上旧任务双跑两天后,发现数据一致,遂修改脚本切换到线上 topic。切换过程如下
- 暂停测试 supervisor,显示 SUSPENDED。
- 等待 supervisor 还在运行的 task 完成,手动 kill。
- terminate 掉测试 supervisor。
- 提交修改 topic 源后的 supervisor spec。
因为设置了任务 task_duration 为 7200s,即实时摄入的 segement 每两个小时发布一次。在未到达发布周期前,任务运行正常。到达发布周期后,任务开始报 segement 发布失败。任务自动拉起后,失败的 segment 被移除,其元数据记录在 druid_pendingSegement 表中,在下游 BI 上的表现就是上个数据周期内数据丢失。
开始查找问题原因,task log 中只有上述错误信息。segment 的发布涉及到 middlemanager 和 overload 进程。查看 overload log,搜索 datasource 名或者 topic 名称,发现如下 error。新的元数据中 topic offset 和旧的元数据中的 topic offset 不匹配。
1 | Not updating metadata, existing state[KafkaDataSourceMetadata{SeekableStreamStartSequenceNumbers=SeekableStreamEndSequenceNumbers{stream='${test_topic}', partitionSequenceNumberMap={0=38254782, 1=38220215, 2=38217021, 3=38232724, 4=38230157, 5=38219118}}}] in metadata store doesn't match to the new start state[KafkaDataSourceMetadata{SeekableStreamStartSequenceNumbers=SeekableStreamStartSequenceNumbers{stream='${product_topci}', partitionSequenceNumberMap={1=38220215,2=38217021}, exclusivePartitions=[]}}]. |
看到这里的想法是找到对应的元数据并修正。查看元数据库,scan 了 druid_segments,druid_tasks 等几张元数据表,并没有发现存储 offset 信息的地方,怀疑是存在 zk 上。查看 druid_pendingSegments,发现存在未被移交的 segment 信息都在这里,查询目标 datasource,存在 124 个处于 pending 的 segment。
看起来是终止 supervisor 后,还存在未被发布的 segment。切换 topic 后,元数据一直更新检查失败,进而导致后续的 segment 全部发布失败,并且发布失败的 segment 被‘丢弃’掉。
此处参考了 https://www.codeleading.com/article/33392556609/ 的方法,清除对应 datasource 的 pendingSegement 中的元数据后,再重新提交 supervisor spec 即可。
这个错误也告诉我们在终止 supervisor 前要验证剩余未发布的 segment 是否被正确处理,在做其他操作。
正式集群和测试集群某些配置相同引发的稳定性问题
正式集群和测试集群的 druid.indexer.task.hadoopWorkingPath 配置相同,但是两个集群的账号权限不一样,导致同一个目录下存在两个账号写入的文件,线上摄入任务在处理不同账号文件时报了权限错误。
这里碰到的具体问题其实是算 uv 类指标时,生成的 build-dict job 在删除过期版本字典时没有权限,导致整个 MR 失败。因为开源版本不支持精确去重,生产上用的是快手打的 patch 包,这里的详细原因开源不一定碰的到,就不细说了。
这件事情得到两个教训:
- 测试 datasource 不要和正式环境的 datasource 重名。
- 在配置测试集群时要明确配置含义,尤其是存储相关的配置。
druid hadoop_index 摄入报错, java.lang.IllegalStateException: JavaScript is disabled?
0.19.0 之前版本的 bug,在使用 js 解析并且设置 targetPartitionSize 相关分区参数时,启动了 determineHashPartitions job 会触发此错误。可以参考 PR#9953。
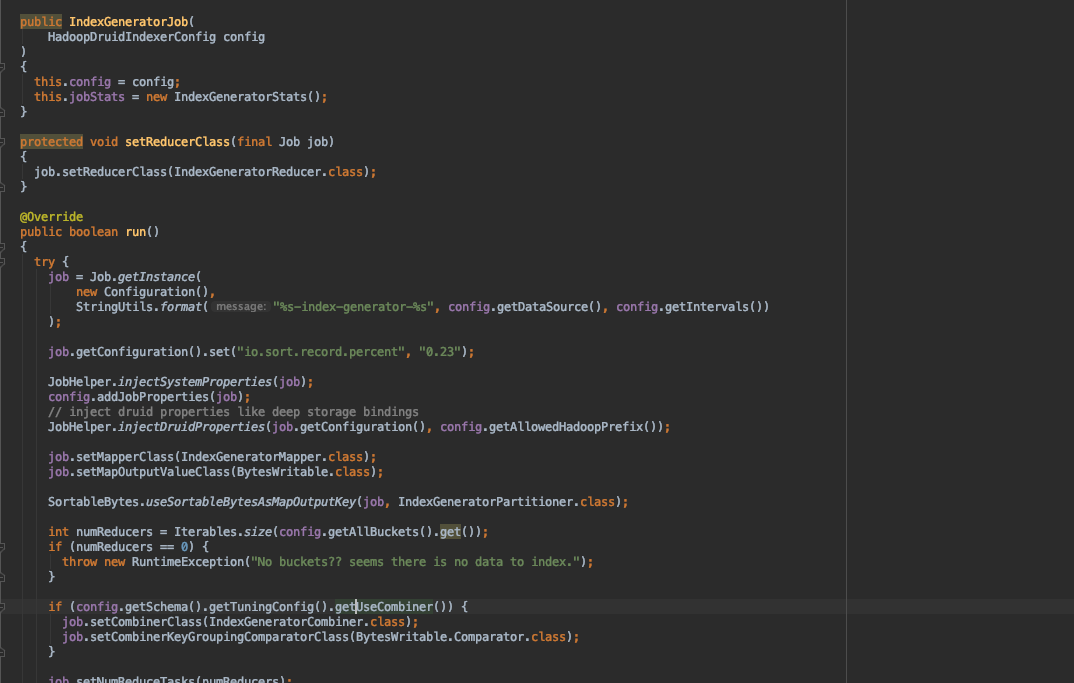
生产上使用的是 0.16.0 版本,查看代码如下,DetermineHashedPartitionsJob 没有调用该方法 JobHelper.injectDruidProperties(job.getConfiguration(), config.getAllowedHadoopPrefix()); ,导致 mapreduce.map.java.opts,mapreduce.reduce.java.opts 没有加载上 druid.javascripts 参数,最终整个 job 就会产生 JavaScript is disabled 错误。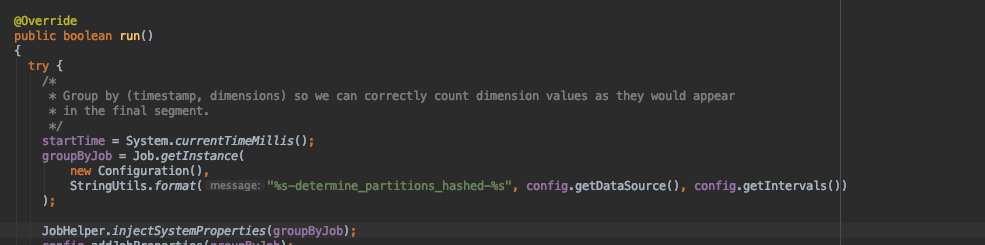
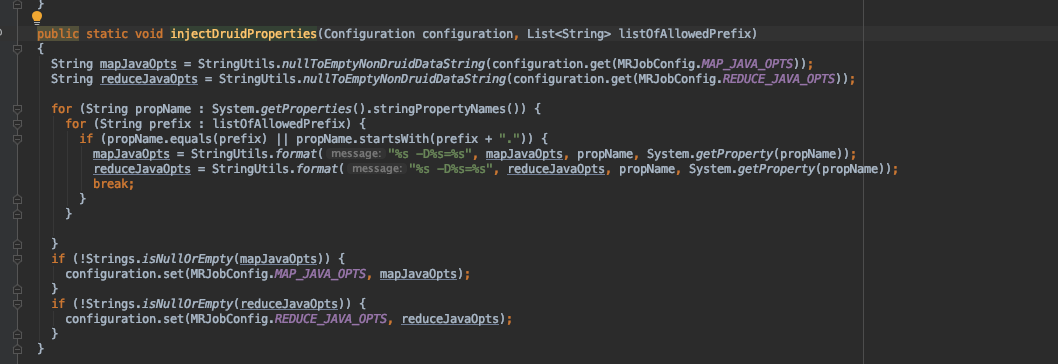
indexGenerator 和 buildDict job 都调用了该方法,所以不会报错。只会在产生 determineHashPartitions job 时报错。